이미지 인식 대회의 2012년 winner였던 alex net의 논문을 리뷰한다.
당시 압도적인 성능을 보였던 뿐만아니라 후대의 신경망들에 큰 영향을 미쳤다
1. Architecture

총 8개의 층을 가지는데 5개의 conv층 + 3개의 fc층을 가지며 GPU 두개로 병렬처리한다.
- ReLU
- gpu 2대 병렬처리
- Local response norm
- overlapping pooling
- dropout
- agumentation
이러한 특징을 가진다.
2. Dataset
- train 1.2m / validation 50000 / test 15000 images
- 모든이미지를 256*256으로 통일 시켜 사용 (256*256*3)
- 직사각형 이미지의 경우 짧은 면을 256으로 조정하고 가운데를 중심으로 자름
3. Architecture Detail
3-1. ReLU
전통적으로 쓰이던 tanh나 sigmoid를 사용하지 않고 ReLU를 사용했다.
아래 그래프에서 보이듯 error가 0.25에 도달하기까지의 epoch가 많이 차이난다.
3-2. Multiple GPUs
당시 gpu로는 메모리가 부족으로 사용했다. 몇개의 레이어에서만 서로의 값을 공유한다.
(alexnet에서는 어쩔수 없었지만 이 방법이 후대의 경량화 모델에 많은 영감을 주었다)
3-3. Local Response Nomalization
ReLU를 Saturated 부분이 없지만 그 값이 무한히 커질 가능성이 있어 너무 큰 값이 주변 값들을 무시할 수도 있다.
AlexNet에서는 ReLU 결과 값을 Normalization 하여 일반화 된 모델을 만들기 위해 Local Response Normalization (LRN) 을 사용했다.
논문에서는 k=2, n=5, alpha = 10**-4, beta = 0.75 를 사용했다.
채널중에서 n = 5기 때문에 만약 7번째 채널을본다면
5,6,7,8,9 이렇게 앞뒤로 같은 위치의 액티배이션값을 제곱한 한것을 분모에 두어 정규화한다.
이는 lateral inhibition(측면억제)이라는 실제 우리의 뇌에서 일어나는 증상을 본따 만든것으로 위의 그림을 보면 흰색선에 집중하지 않는다면 회색의 점이 봉니는데 이는 흰색으로 둘러싸인 사각형에서 억제를 발생시키기 때문에 흰색이 반감ㅇ되어 보이는것 입니다. LRN도 이렇게 relu로 아주 커진 값을 주변에 맞게 억제하는 방향을 원합니다.
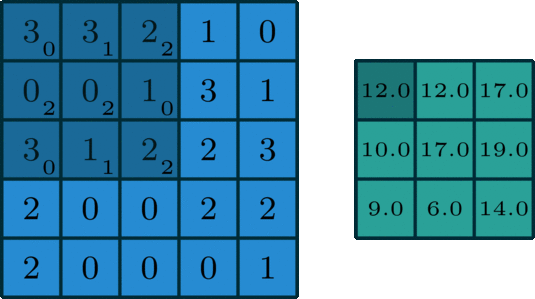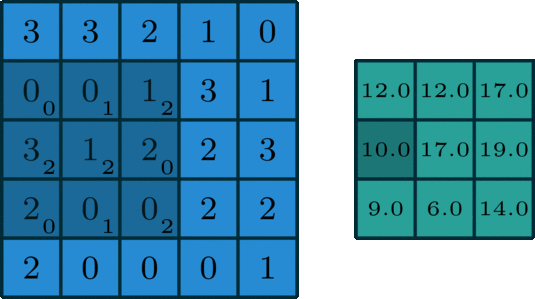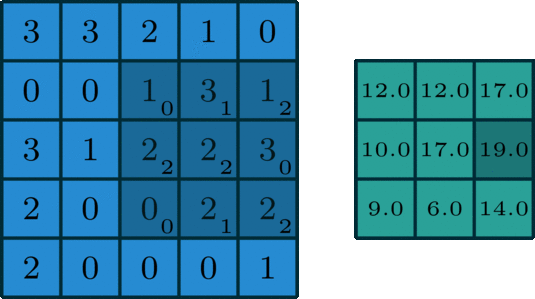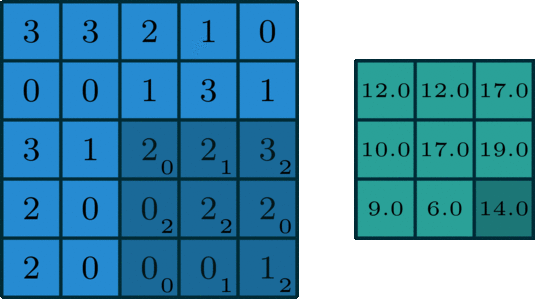
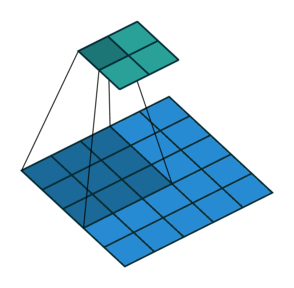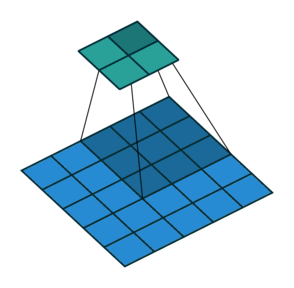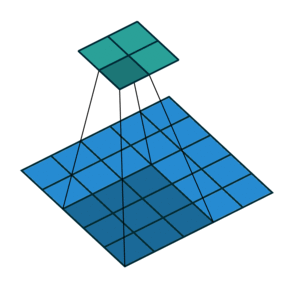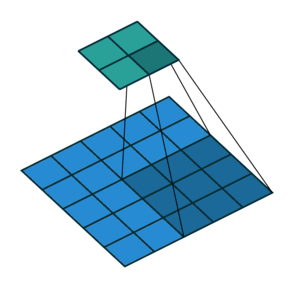
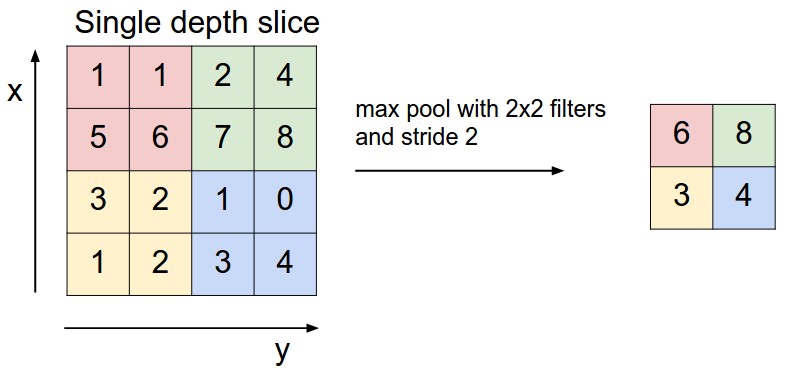
3-4. Overlapping Pooling
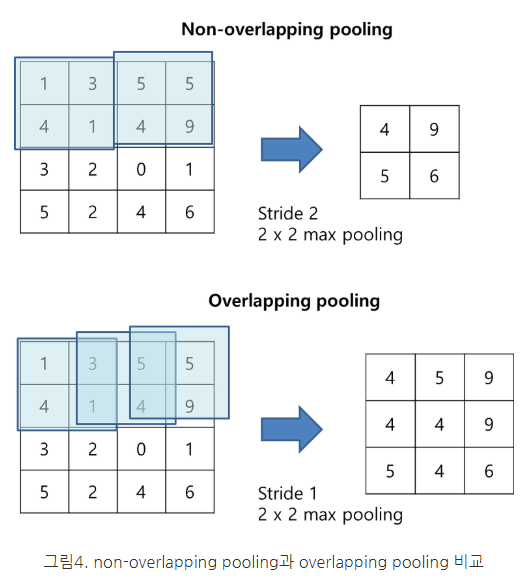
오버래핑 풀링은 stride를 풀링 사이즈보다 작게 가져가 겹치는 부분이 생기게 하는 기법인데 이런 풀링 방법을 적용하여 과적합을 방지했다고 한다.
예를 들어 위 예의 경우 2번째 사각형의 5는 왼쪽 사각형의 4에비에 큰 자극임에도 불구하고 일반 풀링의 경우 5는 사라지게 된다 하지만 오버래핑풀링의 경우 5의 정보가 남게 되는 것이다.
이는 오버피팅을 방지하는 효과를 가져왔지만 풀링 이후의 사이즈가 작아지는 정도가 일반 풀링에 비해 크긱 때문에 연산량 메모리 측면에서 좋지않아 추후의 모델에서는 잘 사용되지않는 테크닉이다
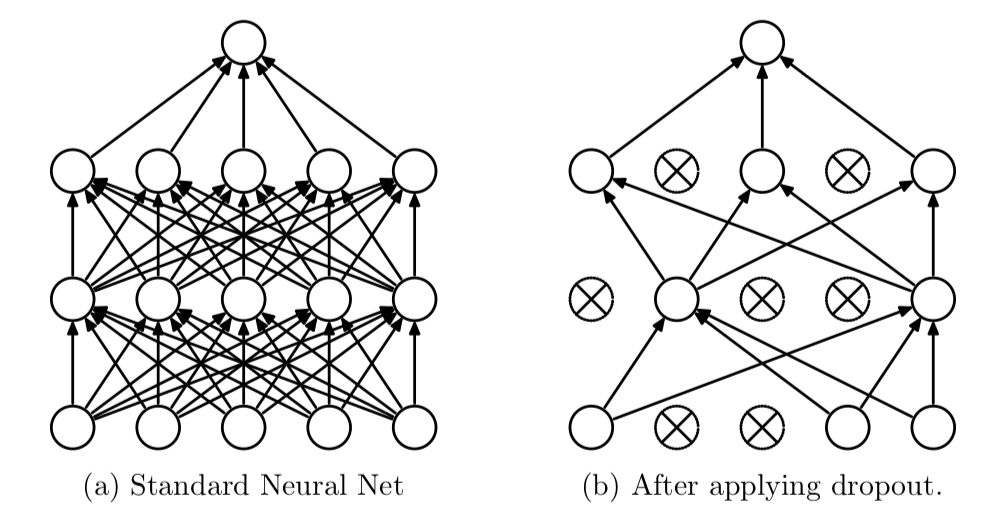
3-5. Drop out
과적합을 방지하기 위해서 drop아웃을 사용했다. 이는 학습시에만 사용되었으며 예측시에는 사용되지않느다.
co-adaptation
= 신경망의 학습 중, 어느 시점에서 같은 층의 두 개 이상의 노드의 입력 및 출력 연결강도가 같아지면, 아무리 학습이 진행되어도 그 노드들은 같은 일을 수행하게 되어 불필요한 중복이 생기는 문제를 말한다.
0.5의 드롭아웃을 줘서 co-adaptation을 막았다.
3-6. Agumentation
256으로 자른이미지를 총 10로 증강시키는 기법을 사용햇다

가운데 이미지 + 좌상단 이미지 + 우상단이미지 + 좌하단 + 우하단 이미지 이렇게 5개와
좌우로 반전한것의 5개를 활용해서 10개의 이미지로 증강하여 사용한다.
'CV > classification' 카테고리의 다른 글
| [CV] ResNet (0) | 2022.05.03 |
|---|---|
| [CV] GoogLeNet (0) | 2022.05.02 |
| [CV] VGG Net 리뷰 (0) | 2022.05.02 |
| [CV] Network in Network 리뷰 (0) | 2022.05.02 |
| [CV] ZF Net 리뷰 (0) | 2022.05.01 |