https://www.youtube.com/watch?v=8b1JEDvenQU&t=114s
회귀의 방법보다 겉보기에는 복잡해 보이지만 이전 GB 분류와 XGB의 회귀를 결합한 방법이라서 큰 어려움은 없었다.
regression 의 경우와 마찬가지로 첫 예측은 0.5로 시작한다.


또한 잔차를 기반으로 트리를 생상하여 similarity score(앞으로 SM)을 계산한다.
분류문제에서는 아래의 식을 사용한ㄷ자


먼저 첫 분기점을 15로 두고 좌측노드의 sm을 계산하면

위와 같은 결과를 얻게된다 (lambda = 0으로 가정) 같은 방법으로 우측노드를 계산하면 1이 나오고

해당 분기점의 gain은 1.33 으로 얻어진다.
15가 아닌 다른 기준점으로도 계산을 실시하고 가장 gain이 큰 15를 첫 분기점으로 선택한다.
하위노드에도 같은 방법을 반복한다.

위와 같은경우에는 gain이 더 높은 dosage < 5 를 선택할 것이다
이제 여기서 cover라는 개념이 등장한다.
sm을 계산하는 식에서

빨간박스가 감싸고 있는 부분을 cover라고 하는데 cover가 기준 값을 넘지 못하면 가지치기를 한다고 이해하면 편하다
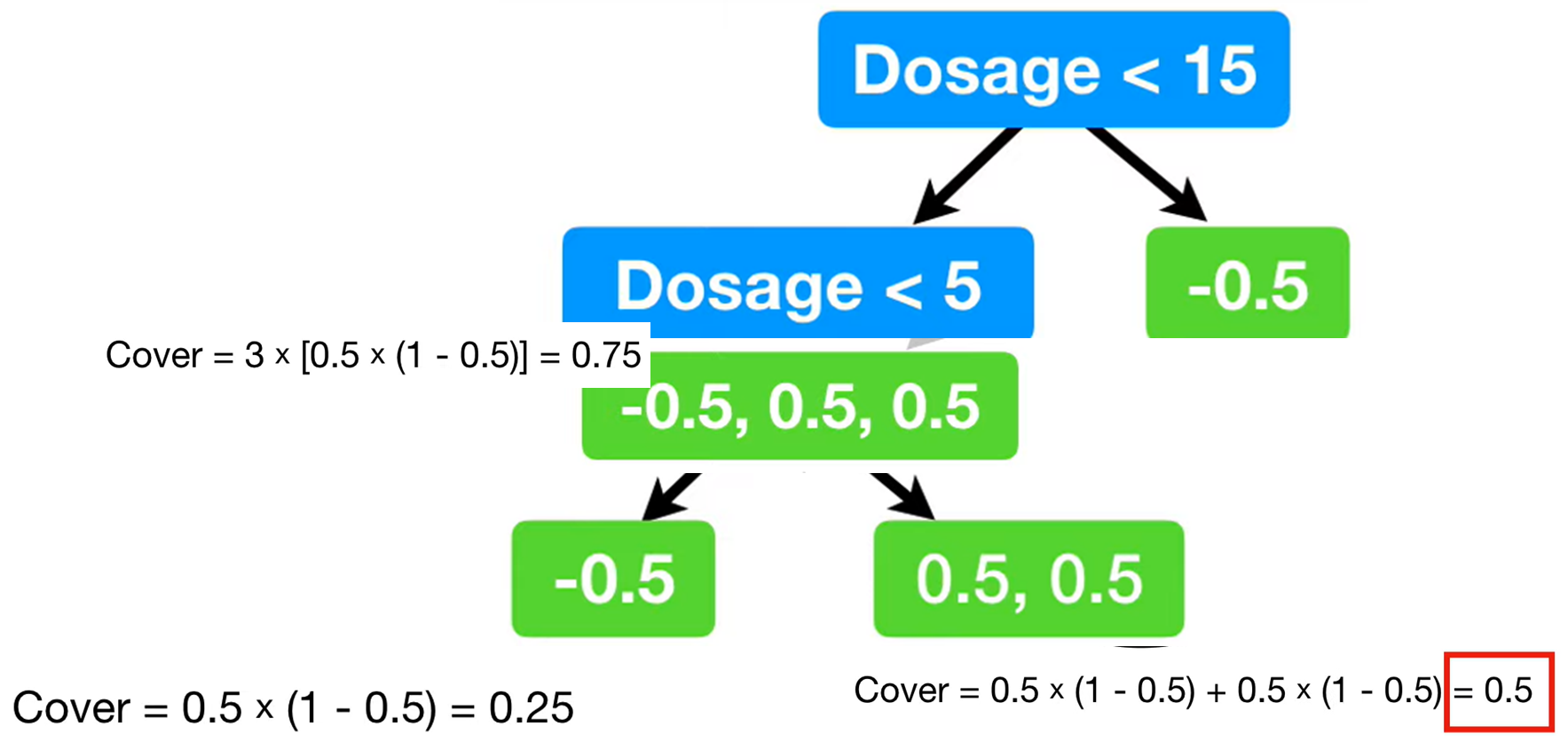
위의 예의 경우 cover가 1을 넘지 못하기때문에 가지치기되게된다.
regression과 동일하게 lambda 에 따라서 gamma를 넘지 못하는 노드 또한 가지치기된다.
이렇게 트리가 완성이되면
output을 꼐산한다.

위와 같은 식으로 결과값을 계산하는데 이는 GB의 결과값에 lambda가 추가된 형태이다.
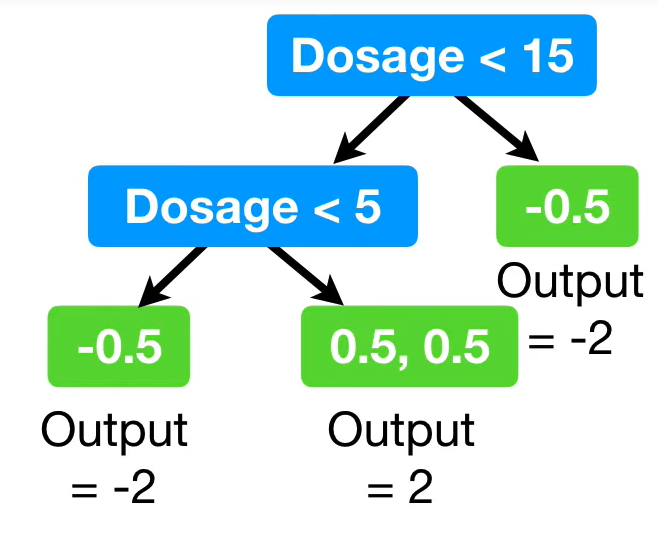
모든 리프노드에 결과를 계산한면 위와같고

GB와 같은 방법으로 새로운 예측값을 계산한다.
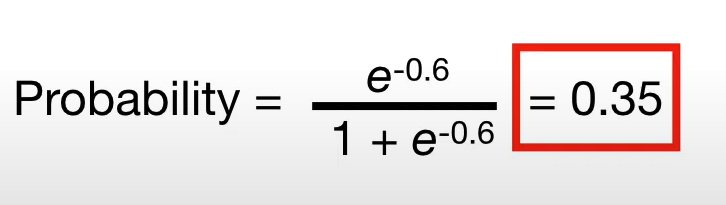
가장 좌측노드의 예측확률은 위와 같게된다.
나온 확률의 잔차를 바탕으로 새로운트리를 만들기를 반복한다.
정리하면 similarity score를 계산한ㄷ,
1. 초기예측값으 0.5로 시작하고 오차를 계산한다
2. similarity score(lambda가 추가되어 좀더 규제된)를 계산하여 각 분기점의 gain을 계산하여 gain값이 높은 분기점을 선택하여 트리를만든다.
3. gamma값보다 gain이 크지않다면 가지치기를 진행한다.
4. 가지치기가 완료된 트리의 예측값을 계산한 후(lambda 반영) learning rate를 반영하여 예측값을 업데이트한다.
예측값은 이전예측과 새로운예측 모두 로짓변환을 하여계산
5. 예측값을 바탕으로 다시 1~4의 과정을 중단규칙이 만족될때까지 반복한다.
'ML' 카테고리의 다른 글
| [ ML ] 인공신경망 기본 (0) | 2022.02.16 |
|---|---|
| [ML] cycling encoding (0) | 2022.02.15 |
| [ML] XGBoost - Regression (0) | 2022.01.04 |
| [ML] Gradient Boost - Classification (0) | 2022.01.03 |
| [ML] Gradient Boost - regression (0) | 2021.12.30 |