adaboost 는 stump의 오차를 이용하여 더 나은 stump를 만드는 과정이었다.
그에 반해 gradient boost(앞으로 GB)는 리프노드로 부터 첫예측을 실시하고 그에 대한
잔차를 바탕으로 새로운 트리를 업데이트해나가는 과정이다. 그 잔차를 계산함에 있어서 미분이 사용되어 gradient(기울기) boost라 불린다.

loss function의 미분값이 다음학습의 정답이 된다.
트리모델의 특성상 트리의 깊이가 깊어지게되면 과적합의 위험이 큰데 이를 방지하기위하여 크기가 제한된 트리를 이용한다. 물론 ada boost의 stump보다는 크기가 큰 트리이다.
가장 보편적인 방법으로 GB를 설명하겠다..

위와 같은 데이터가 있다고 가정할 때 가장 편하게 데이터를 예측할 방법은
데이터의 평균값을 이용하는 것일 것이다.
GB는 평균값을 첫 예측값으로 이용하고 예측값과 관측값의 오차를 바탕으로 새로운 트리를 만들어 낸다.
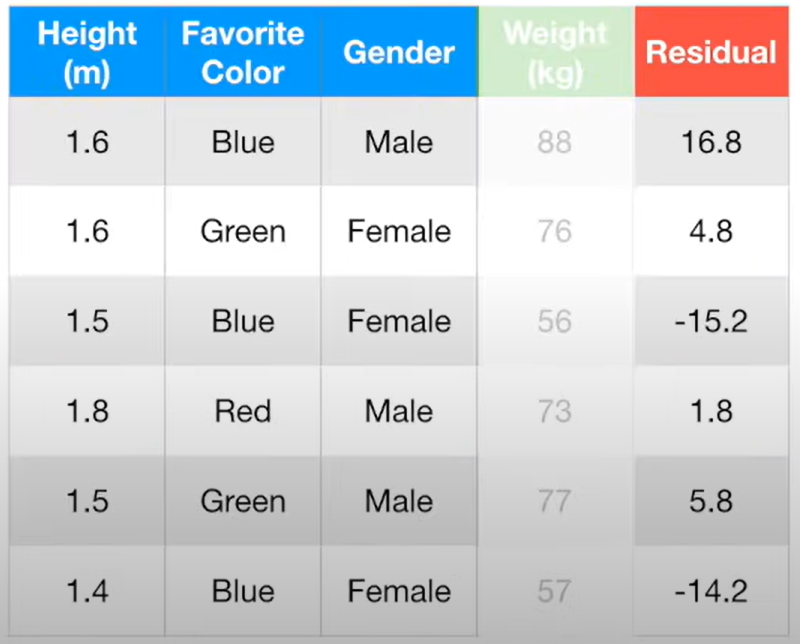
각 잔차를 계산하면 위와 같은 결과가 얻어지는데
이제 산출된 잔차를 바탕으로 트리를 만든다.
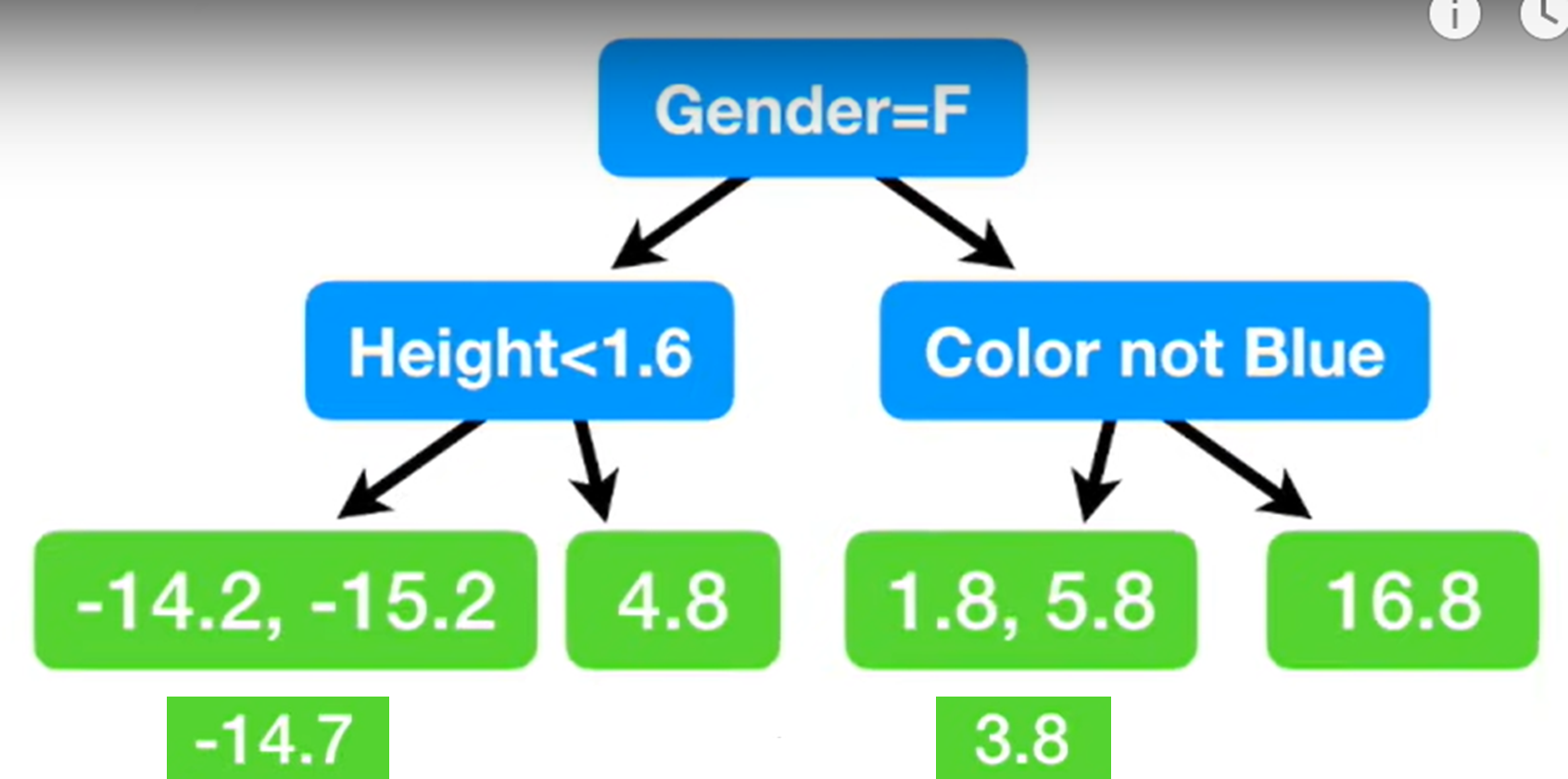
잔차를 예측하는 decision tree를 만들게 된다,

잔차를 바탕으로 위의 row를 예측하면
88이라는 정확한 예측결과를 얻을 수 있다.
하지만 저 값은 과적합된 결과일 수 있다. 실제로 샘플데이터가 굉장히 작아서 과적합이 발생한 것이다.
그렇기에 GB에서는 learning rate라는 개념을 사용한다.

잔차에 learning rate를 곱해 원예측값에 더한 값을 새로운 예측값으로 활용하게된다.

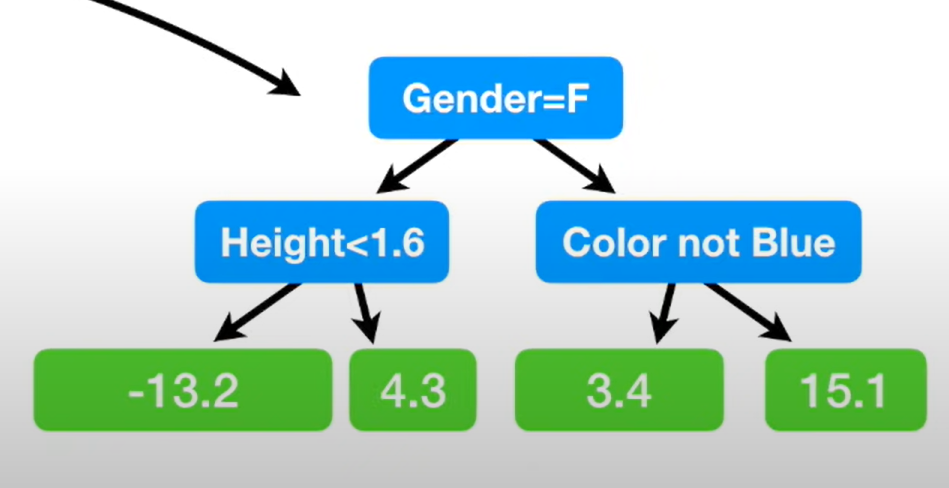
이제 만들어지 두번째 잔차로 두번쨰 트리를 만들어 위의 과정을 반복한다.
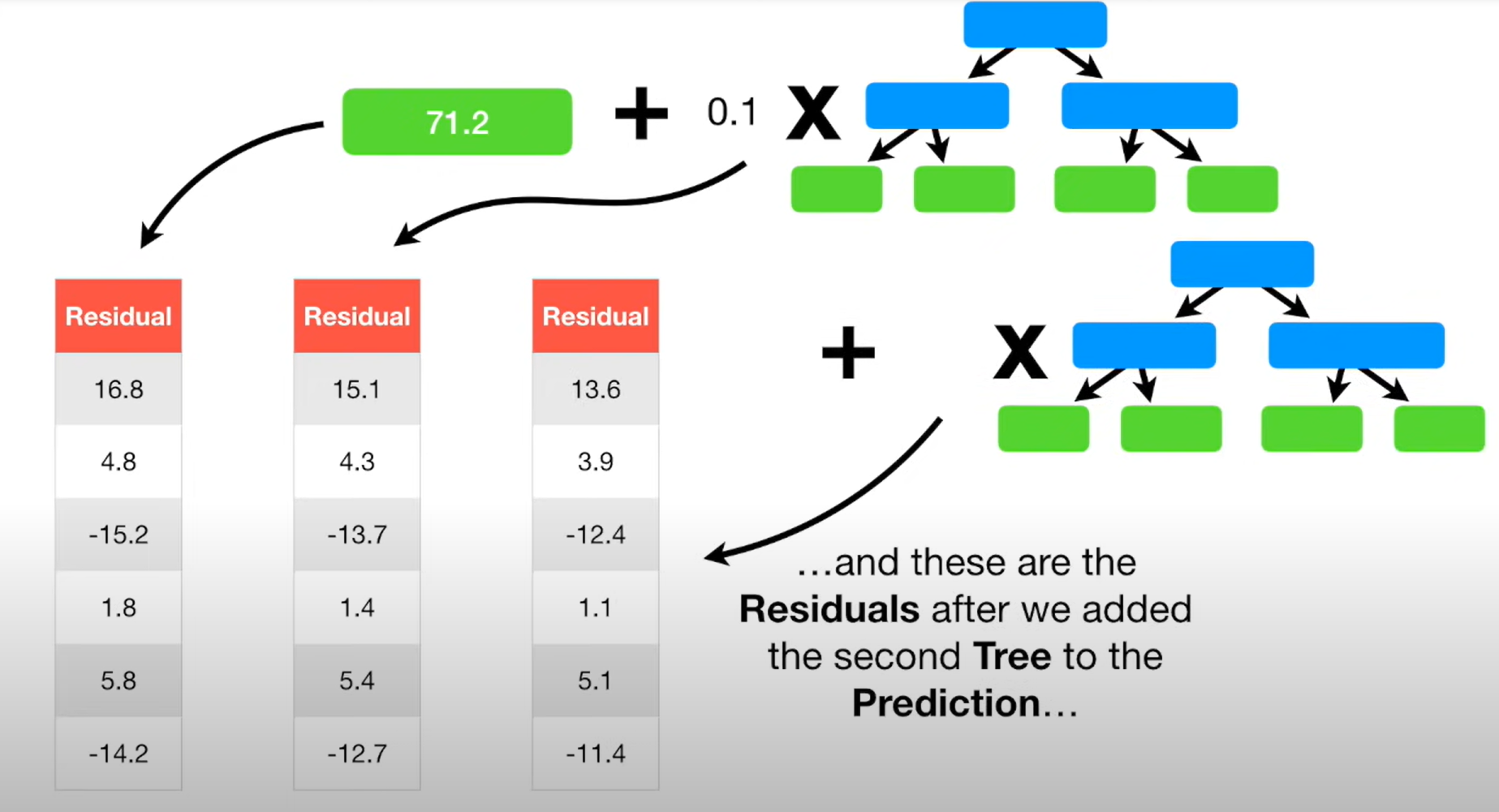
GB 미리 설정한 중단조건을 충족하기 전까지 위의 과정을 반복한다. 과적합을 피하면서, 점점 원 관측값에 가까워지는 것이다.
정리하면
1. 첫 예측값은 target의 평균
2. 예측값을 바탕으로 오차를 예측하는 트리생성
3. 예측값 + 트리로 예측한 오차 * leanig rate로 예측값을 업데이트
2~3을 중단조건이 만족될 떄가지 반복
'ML' 카테고리의 다른 글
| [ML] XGBoost - Regression (0) | 2022.01.04 |
|---|---|
| [ML] Gradient Boost - Classification (0) | 2022.01.03 |
| [ML] Adaboost (0) | 2021.12.29 |
| [ML] Randomforest (0) | 2021.12.29 |
| [ML] Regression Tree (0) | 2021.12.28 |