1. 부스팅이란?
여러모델을 결합하는 것을 앙상블이라고 하는데 앙상블은 배깅과 부스팅 두가지로 나뉜다.
간단히말하면
배깅은 여러데이터를 샘플링하여 각자 독립적인 모델을 만들고 각각 같은 가중의 투표를 하는데에반해
부스팅은 한모델을 만들고 그 모델의 오차를 바탕으로 다음모델을 만든다. 그후에 그 각각의 모델이 설명을 얼마나잘하는지에 가중치를 두어 그 가중치에 맞춘 최종리턴을 선정한다.
2. Adaboost
에이다부스트는 부스팅 모델의 가장 기본적인 형태이다.
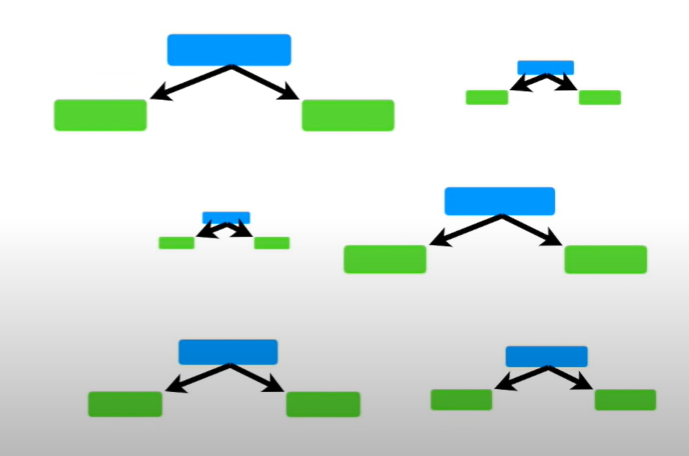
에이다 부스트의 가장 큰 특징이라고 한다면 분기점이 한번을 이후로 나눠지지 않는다는 것이다. 즉 바로 리프노드가 나오는 구조이다. 이런 구조를 tree라고 하지않고 stump라고 한다.
1) 이런 약한 학습모델인 stump들을 결합시킨 것이 adaboost이다.
2) 각각 stump들은 각자의 amount of say(설명력)을 가진다
3) 각각의 stump들은 이전의 stump의 오차에따라 변화한다.
위의 세가지 개념을 가지고 adaboost는 이루어진다.
2-1. sample weight

adaboost부터는 sample weight라는 개념이 처음으로 등장한다. 최초의 sample weight는 1/전체 자료의 수 이지만
만들어진 stump가 얼마나 잘예측했는지에따라서 weight가 업데이트된다.
간단히 짚고 넘어가자면 현재 stump가 예측을 잘못한 데이터일수록 sample weigh값이 올라가고 다음 모델을 위한 학습 데이터에 포함될 확률이 올라간다.
stump를 만드는 것부터 차근차근히 과정을 살펴보자
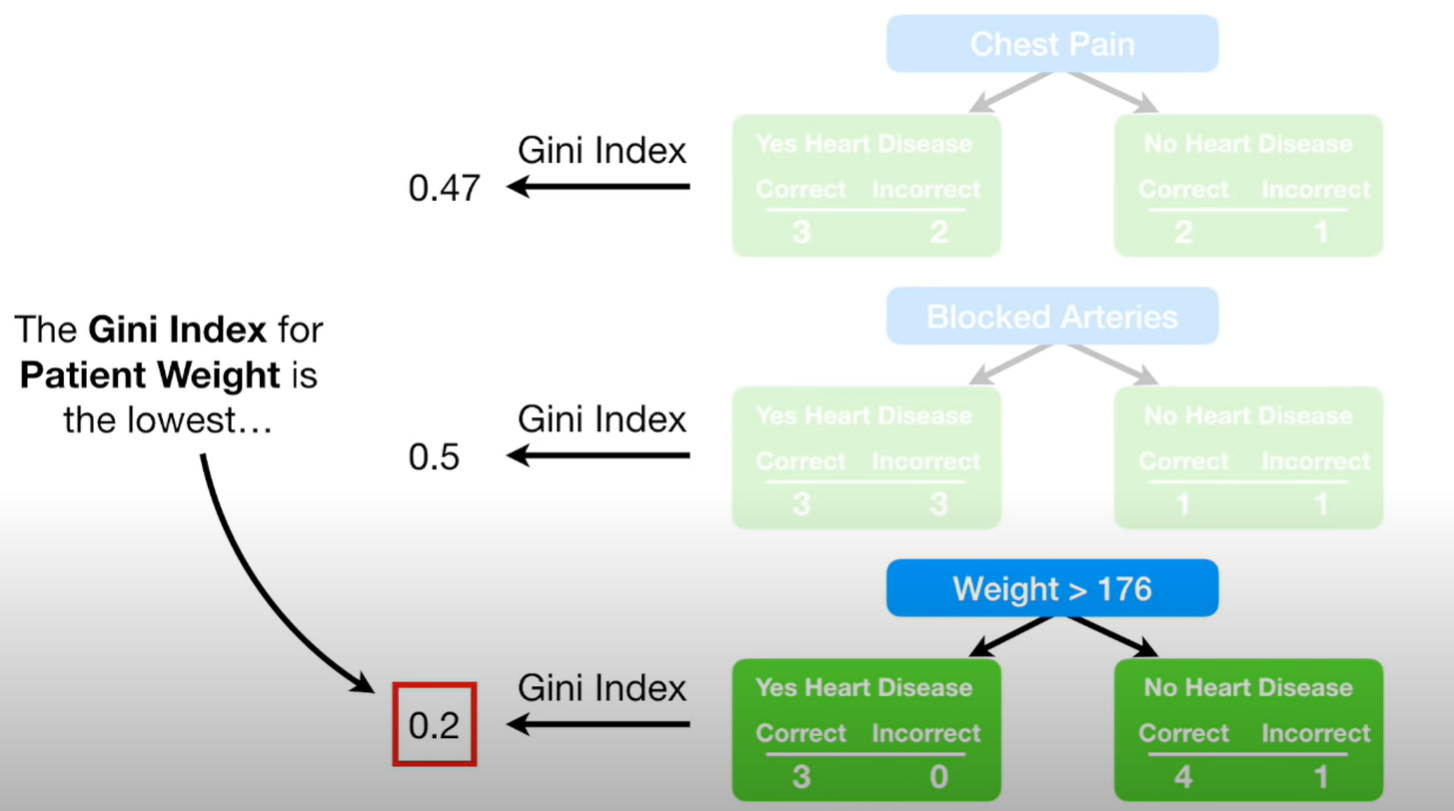
먼저 스텀프를 만들때에 decision tree의 첫 과정처럼 지니계수를 비교하여 질문을 선택한다.
위의 예에서는 가장 지니계수가 낮은 weight > 176 이 선택된다.

이후 모델에서 잘 분류한 녀석과 그러지 못한녀석을 식별하여 sample weght를 업데트한다.
이제 이모델의 total error과 amount of sat를 계산한다.
Total Error = 분류에 실패한 녀석들의 sample weght의 합
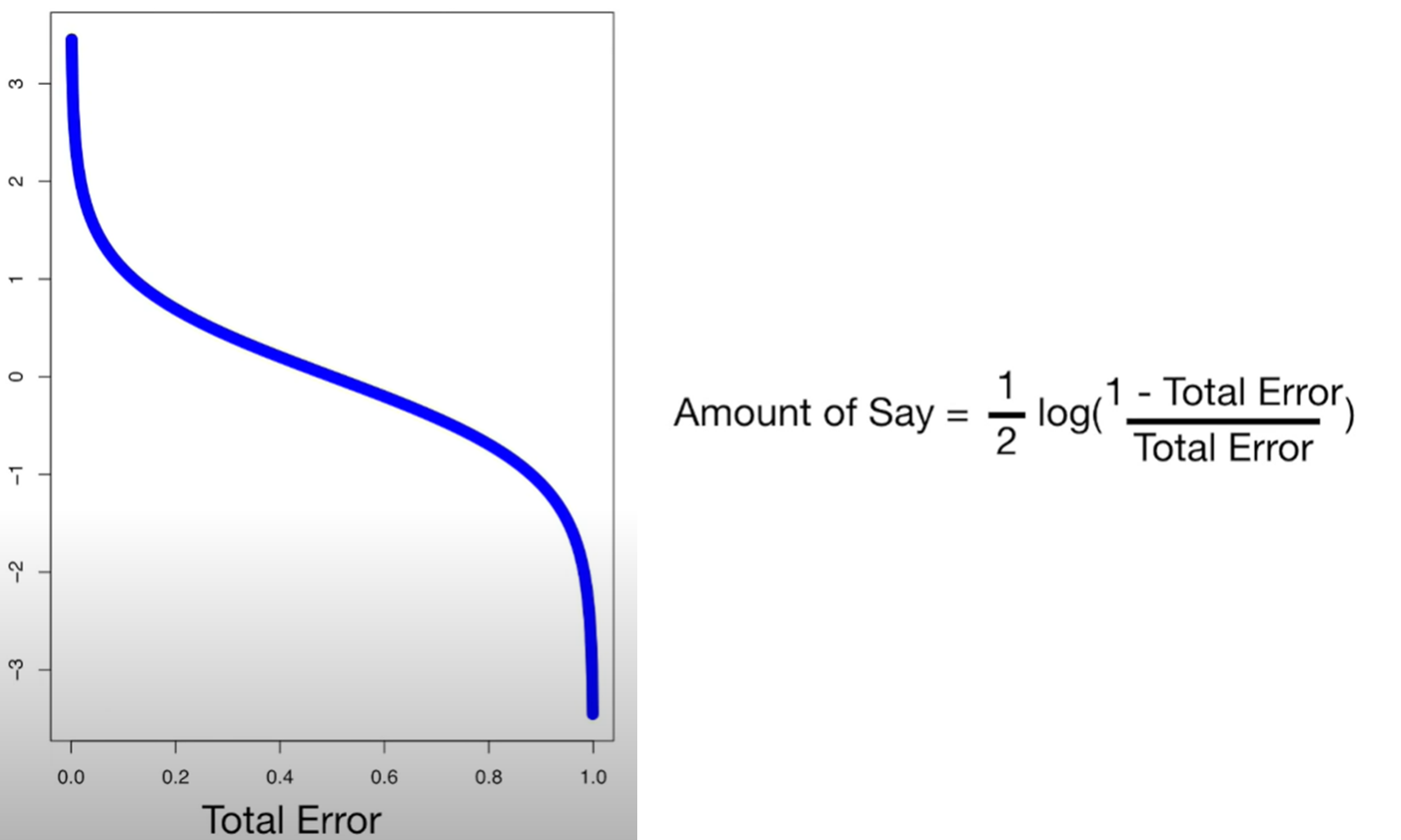
total error가 높아지면 amount of say는 낮아지고
total error가 낮아지면 amount of say는 높아지고
total error가 1/2 이면 즉 분류확률이 반반이면 amount of say는 0 이된다.
이제 이 값으로 대략적으로 이 stump가 데이터를 얼마나 예측하는지를 수치적으로 확인할 수 이있다.
위 예의 total error =1/8 이고 amount of say = 0.97이다.
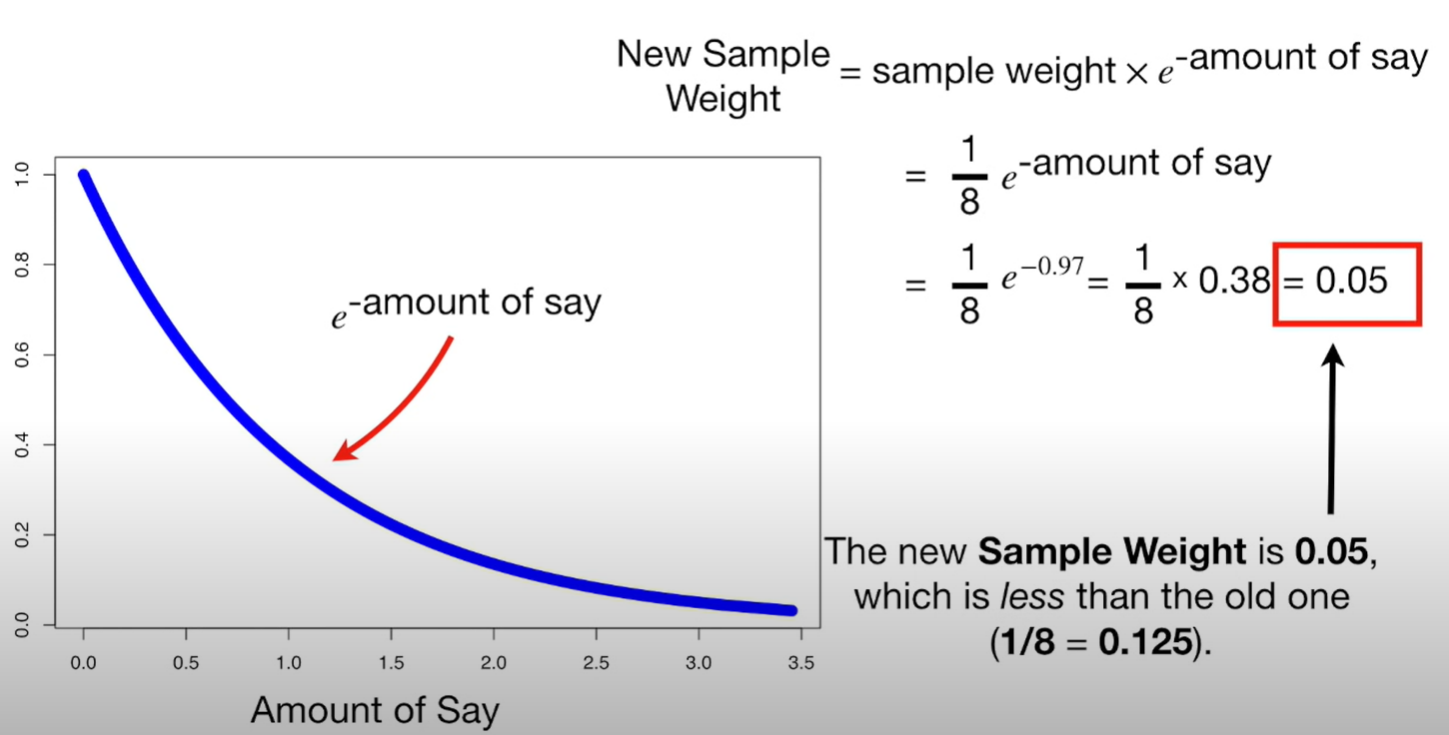
이제 amount of say를 바탕으로 sample weigt를 업데이터해야한다.
잘못분류한 데이터의 경우

위와 같이 업데이트가 되고
잘 분류한경우
이렇게 계산이되고
각각 새로은 가중치를 반영하면
이런식의 표형태가 나온다. 그 가중치를 합이 1이되게 조정을하면 normweight가 나온다.

이제 저 norm weight를 바탕으로 다음 stump의 생성에 사용될 데이터를 샘플링한다..
그 방법은 다음과 같다
0~1 사이의 난수를 생성한다.
난수 0.72은 0.7 보다 크고 0.77보다 작으므로 다섯번째 데이터를 넣는다.
난수 0.42은 0.21 보다 크고 0.7보다 작으므로 네번째 데이터를 넣는다.
난수 0.83은 0.77 보다 크고 0.84보다 작으므로 여섯번째 데이터를 넣는다.
난수 0.72은 0.7 보다 크고 0.77보다 작으므로 다섯번째 데이터를 넣는다.
이런식으로 원데이터의 갯수만큼 반복하여 새로운 데이터를 만든다. 이제 이데이터를 바탕으로 다음 stump를 만드는것이다.

새로운 데이터를 보면 같은 데이터가 4번 반복된다. 첫 stump에서 예측에 실패한데이터에 높은 가중치를 줬기때문에
여러면 샘플링 된 것이다. 이렇게 새로운데이터는 이전 stump에서 실패한 데이터를 더 많이 학습하게 되어있다.
그 이후 새로운데이터에 대해서는 sample weight를 초기화한다.
이런 과정을 여러번 반복하여 여러 stump를 만든다.

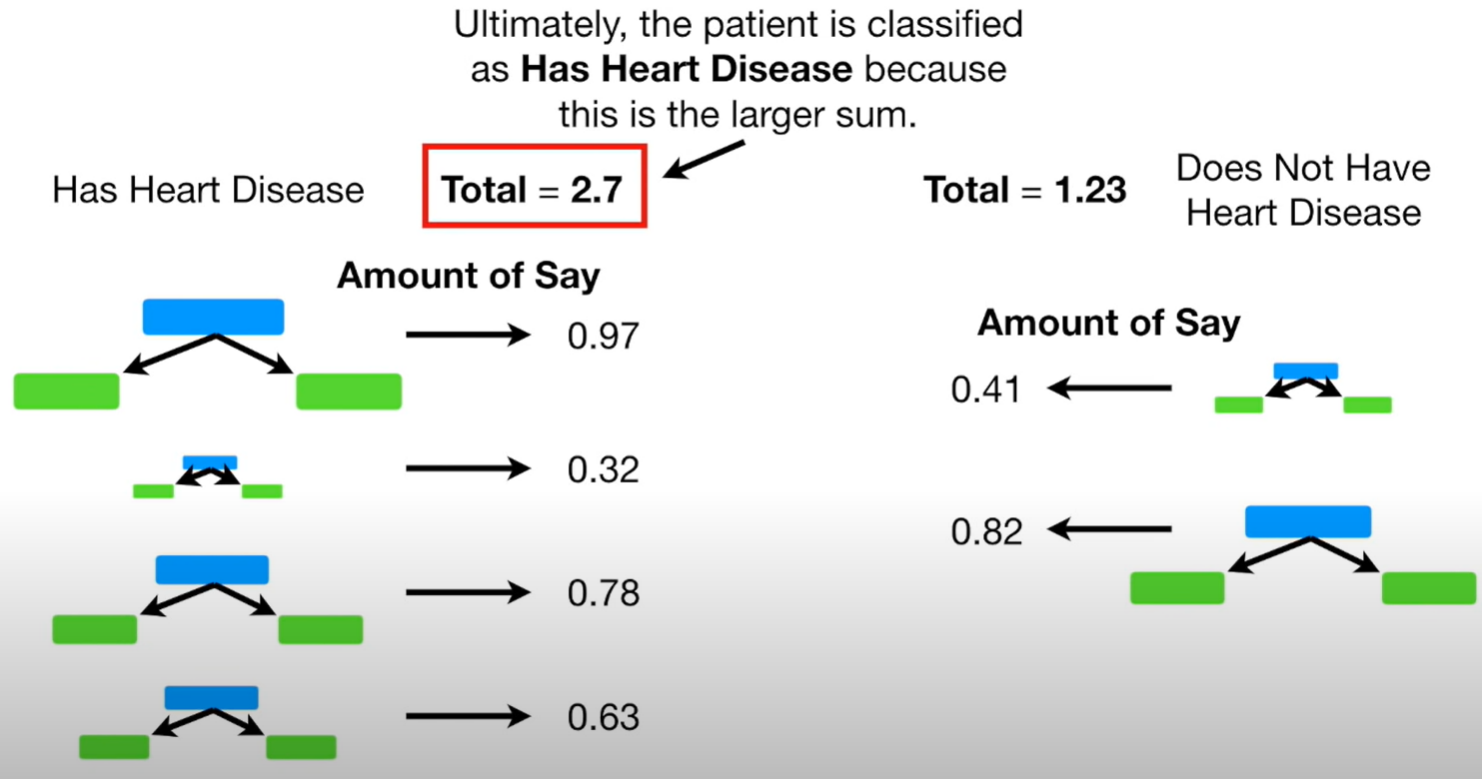
이제 여러 stump를 가지고 최종결과를 찾아야한다.
모두 동일한 투표권을 가지는 배깅과는 달리
adaboosting은 각각 모델의 amount of say의 합을 비교하여 최종결과를 산출한다.
위 예의 경우 한 row를 넣었을때
yes라고 대답한 stump들의 amout of say의합이 no라고 대답한 stump들의 amout of say의 합보다 크므로
해당 row에 대하여 yes라는 결론을 내린다.
스텀프를 만들고 그를 바탕으로 새로운 스텀프를 만들고 반복해 만들어진 여러 스텀프들의 설명력의 합을 비교하여 결론을 내린다
'ML' 카테고리의 다른 글
| [ML] Gradient Boost - Classification (0) | 2022.01.03 |
|---|---|
| [ML] Gradient Boost - regression (0) | 2021.12.30 |
| [ML] Randomforest (0) | 2021.12.29 |
| [ML] Regression Tree (0) | 2021.12.28 |
| [ML] Decision tree (0) | 2021.12.28 |