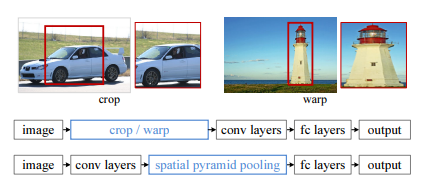
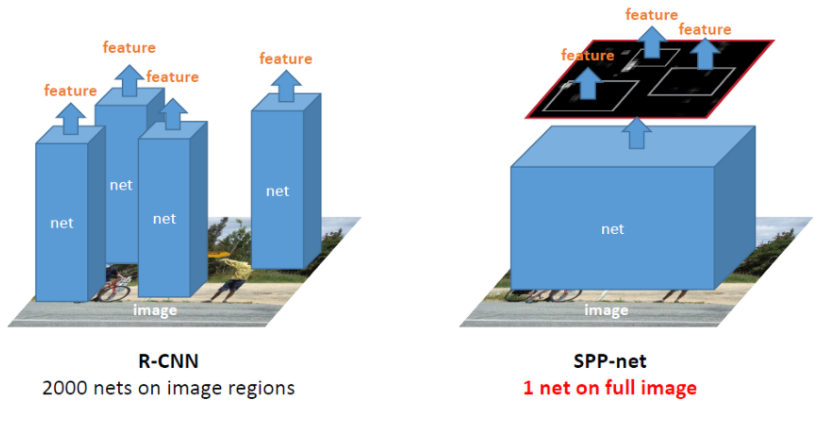
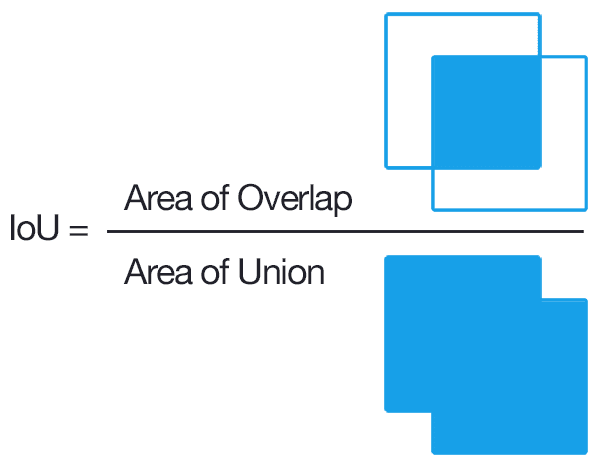
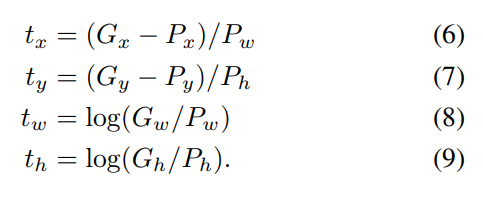spp 넷에서 rcnn의 단점인 2000번의 cnn연산과 warp과정에서 정보손실을 해결했지만
svm과 bbr이 따로 수행되고 svm이 gpu에서 돌아가지 않는다는 단점들은 해결되지않은 상태였다.
이를 해결하며 나온 것이 fast R-cnn이다.
이름에서 볼 수 있듯이 속도면에서 R-cnn에 비해 훌륭했고 정확도도 높아졌다.

fast R-cnn의 과정은 다음과 같다
1. 이미지를 cnn에 통과 시켜 feature map을 얻는다.
2. selective search를 통해 찾은 ROI들을 featuremap에 대응시키고 RoI pooling을 적용하여 고정된 feature vector를 얻는다
3. feature vector를 softmax, bbr에 활용한다.
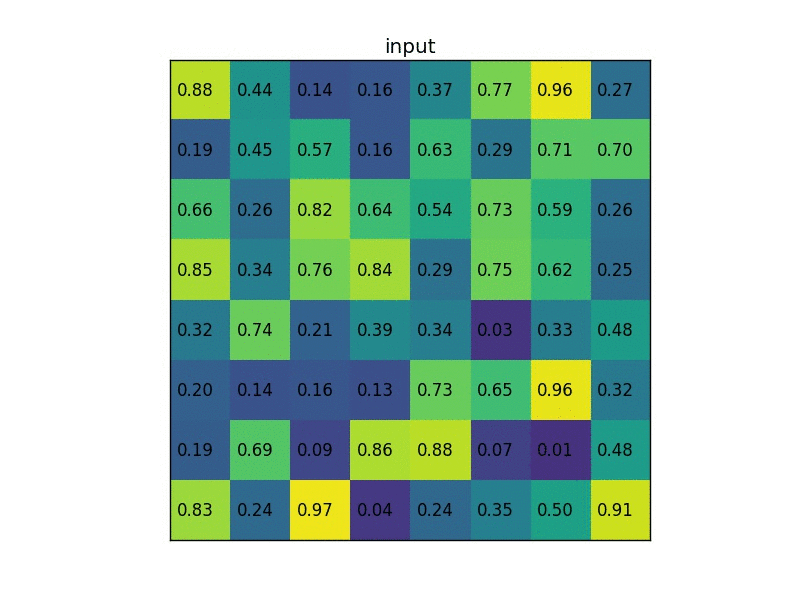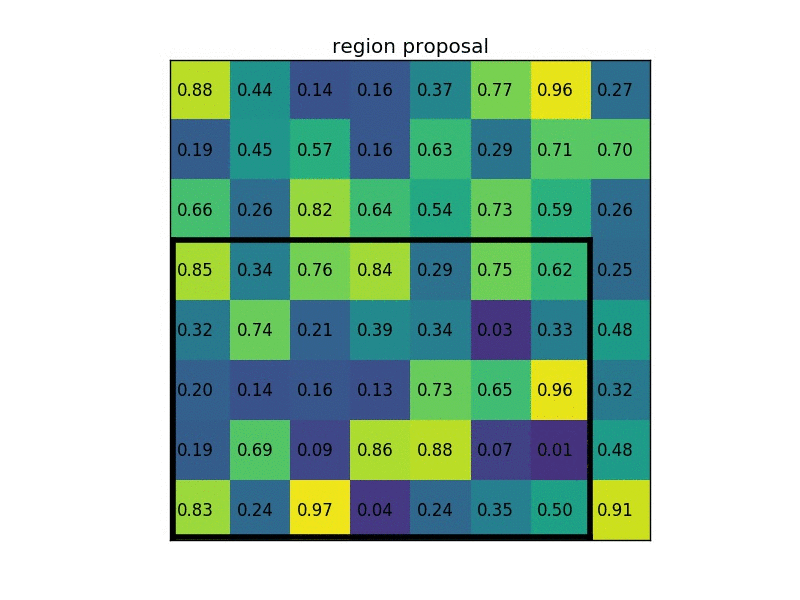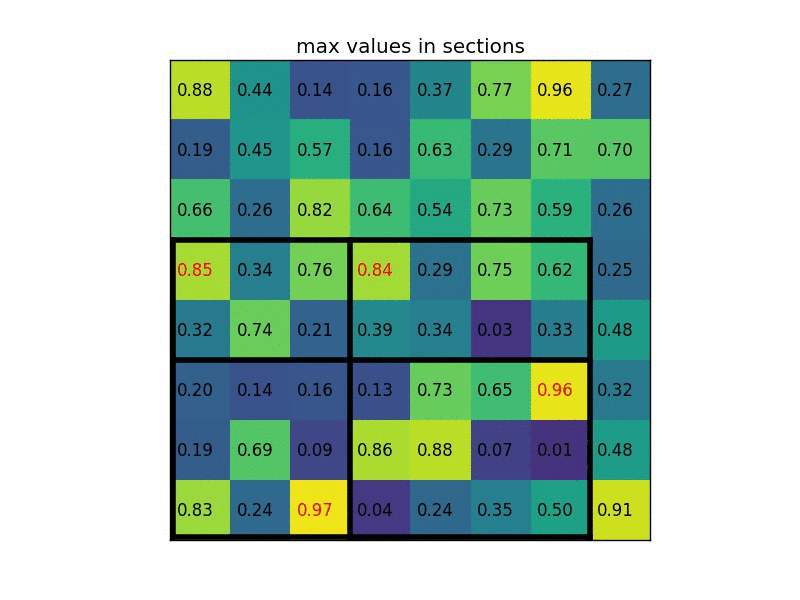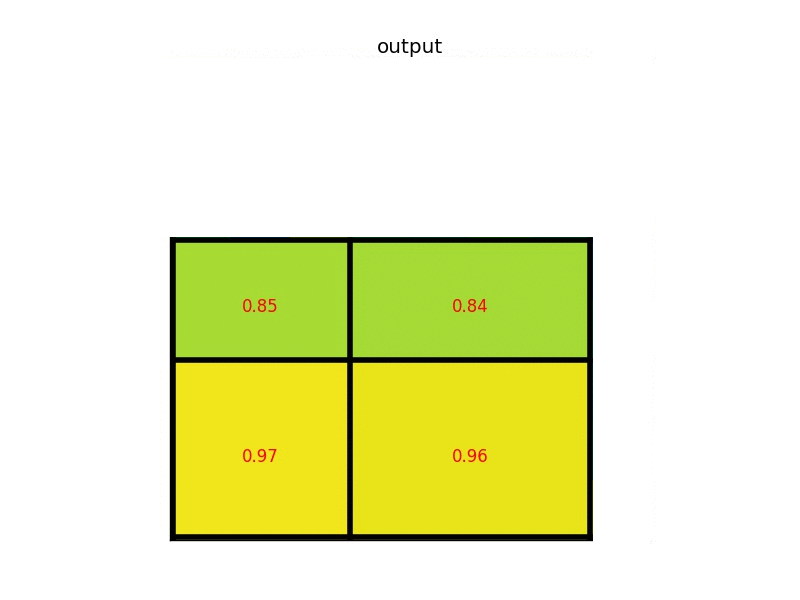
1. ROI pooling
vgg net을 바탕으로 fine tuning을 한다.
spp넷에서 언급했던 피라미드풀링과 비슷한 개념이라생각하면된다. 단 점점 작아지는 모습을 보였던 것과 달리
하나의 레이어만을 사용한다. 여기서는 7x7을 사용하였다
2, Multi task loss
spp net과 rcnn에서는 분류기로 cnn에서 softmax를 사용한 것이아니라 feature만을 추출하여 개별적인 svm 및 bbr을 활용하였다.
하지만 fast rcnn은 classification과 bounding box regression을 적용하여 각각의 loss를 얻어내고, 이를 back propagation하여 전체 모델을 학습시키도록 했다. 이를 위해서는 두개념을 통합한 loss가 필요했는데 아래 식이 Multi task loss이다.

먼저 classification loss부분부터보면
p는 어떤 클래스일지 예측한 확률 (p0, ..., pk) k+1 길이의 벡터이고 u는 해당 roi의 true값이다.

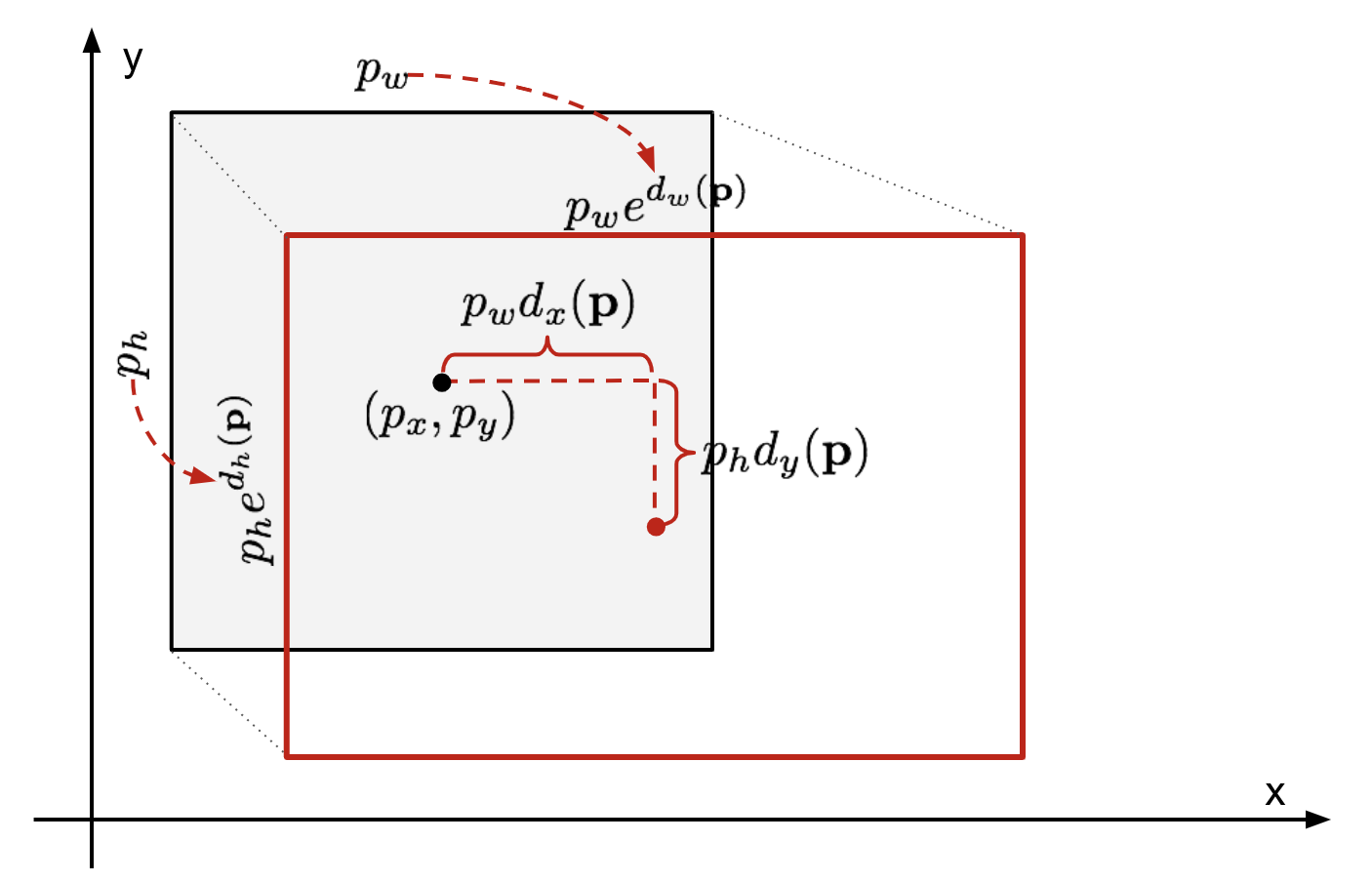
Localization loss를 보면
tu는 tx, ty, tw, tw인 벡터이고 모두 0이상 1이하의 값을 같는 이미지내에서의 상대적인 값을 가진다.

lambda는 두 loss사이의 balancing parameter이다.
하지만 roi를 찾는 과정에서 selective search를 하는 것은 이전과 동일하여 이부분에서 속도향상은 없었다. 이를 faster R-CNN에서 해결한다.
'CV > object detection' 카테고리의 다른 글
| [cv] SPP-net (0) | 2022.06.01 |
|---|---|
| [CV] R-CNN (0) | 2022.06.01 |
| [cv] object detection 기본용어 (0) | 2022.05.25 |