https://www.youtube.com/watch?v=J4Wdy0Wc_xQ&t=42s
모든 이미지와 출처는 위영상으로 부터 가져왔다.
1. Randomforest란
Decision Tree는 overfitting될 가능성이 높다는 약점을 가지고 있다. prune을 통해 트리의 최대 깊이를 설정하여 어느정도 방지할 수 있지만 이 방법으로 overfitting을 해결하기에는 무리가 있다.
Random forest는 여러개의 decision tree를 만들어 예측데이터를 각 트리에 동시에 통과시키고, 각 트리가 분류한 결과에서 투표를 실시하여 가장 많이 득표한 결과를 최종 결과로 선택한다.
랜덤 포레스트 중 몇몇개 트리는 overfitting될 수 있지만, 많은 수의 트리를 생성함으로써 overfitting이 예측하는데 있어 큰 영향을 미치지 못 하도록 방지한다.

2. Randomforest 만들기
decision tree에대한 지식이 부족하다면 이해가 힘들 수 있으니 이전 게시글을 보고오는걸 추천한다.
https://gwoolab.tistory.com/24?category=906381
[ML] Decision tree 수학적으로 알아보기 - 분류
1. 트리기반 모델을 자주사용하지만 모델에 대한 이해가 부족한것 같아 하나씩 작성해보려한다. 참조의 대부분은 https://www.youtube.com/watch?v=7VeUPuFGJHk&t=268s 에서 가져왔다. 2-1. decision tree de..
gwoolab.tistory.com
2-1. bootstraped dataset

랜덤 포레스트를 만들기 위해서는 부트스트랩 데이터셋을 먼저 생성한다.
원본데이터와 같은 사이즈의 부트스트랩 데이터를 만들기위해서는 그냥 랜덤으로 오리지날 데이터 셋에서 추출한다.
단 복원추출을 허용하여 데이터를 추출한다. 같은데이터가 두번이상 추출가능하다는 이야기이다.
2-2. columns 선택
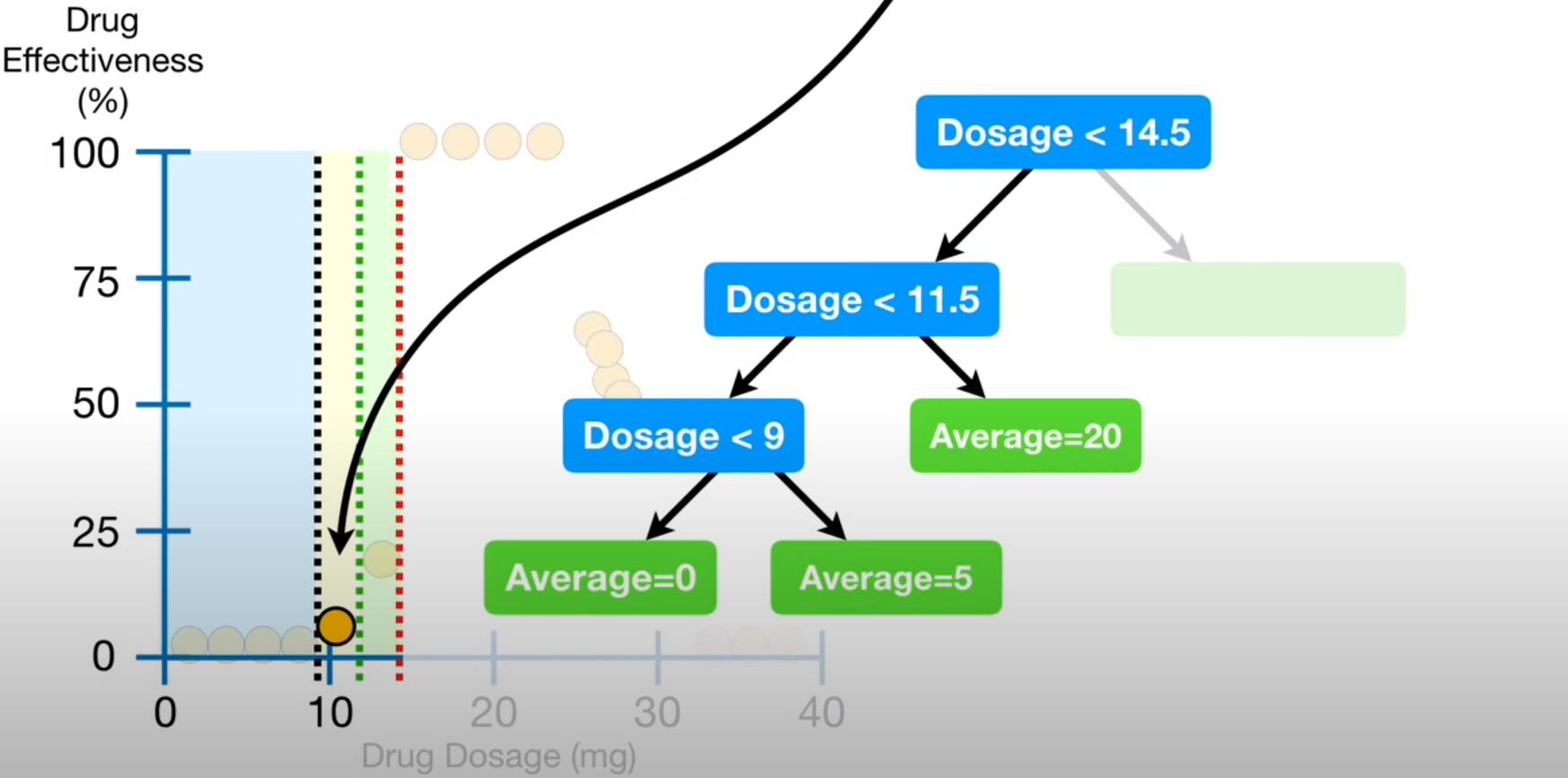
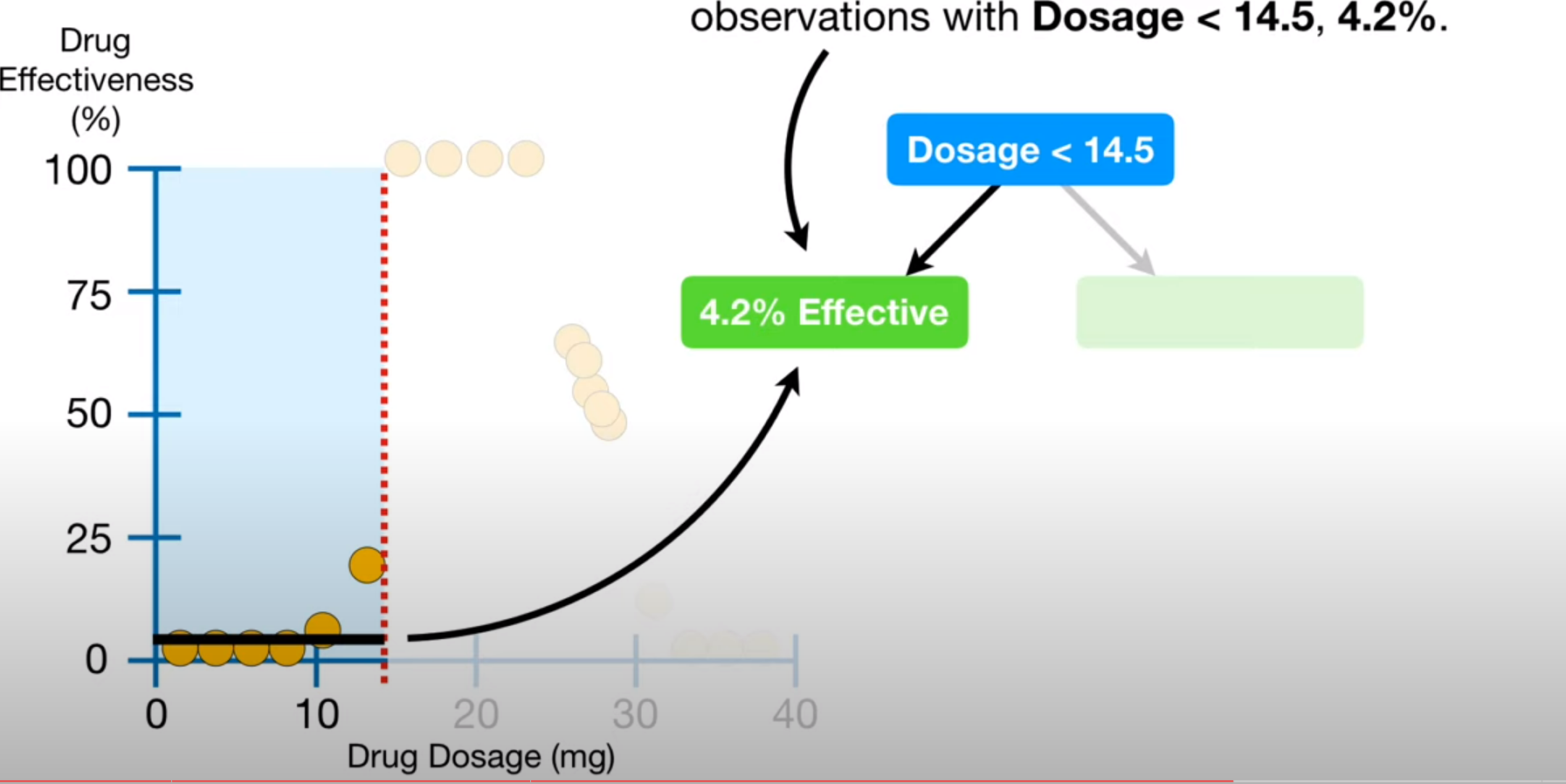
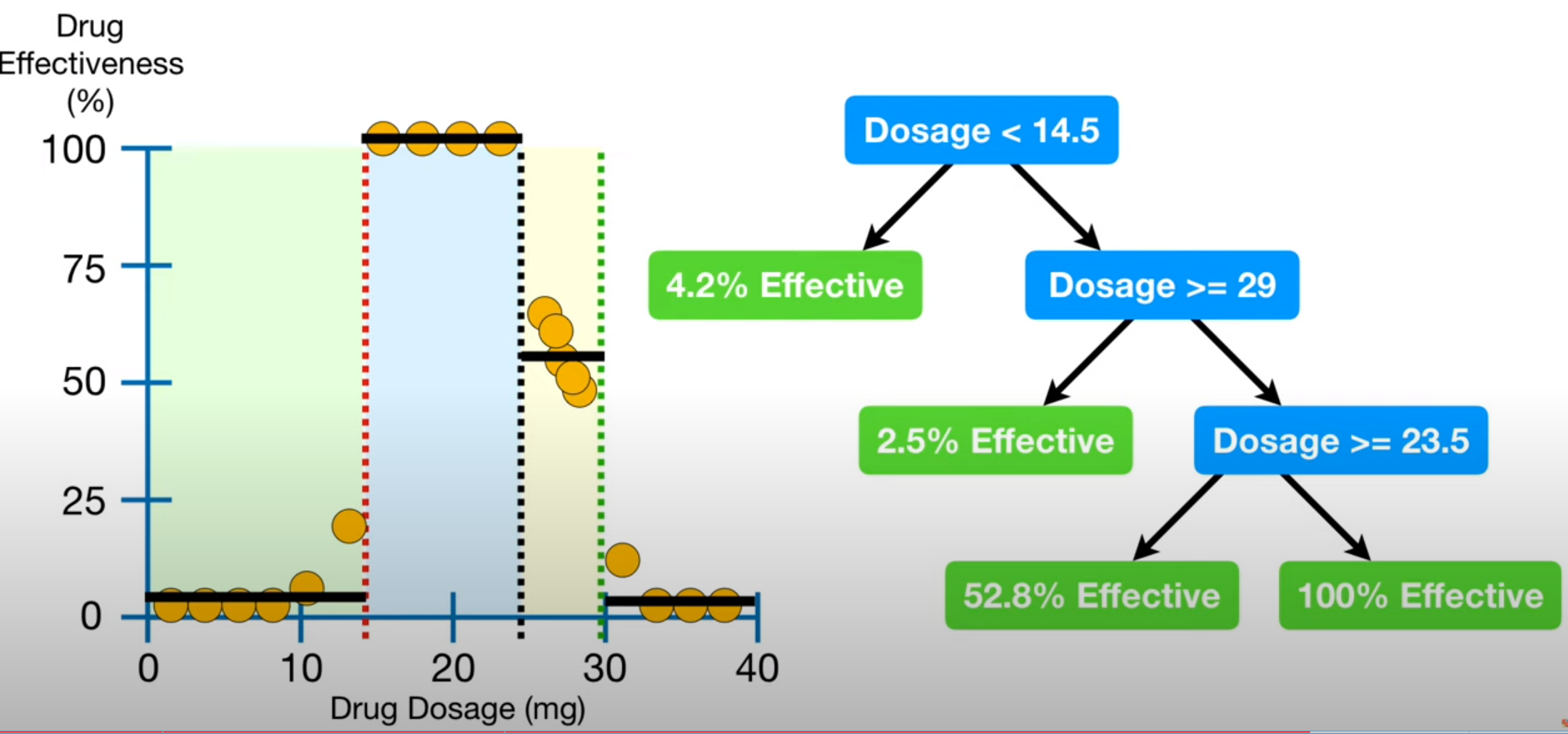
예를 들어 한 단계마다 두가지의 변수를 선택한다고 가정하자

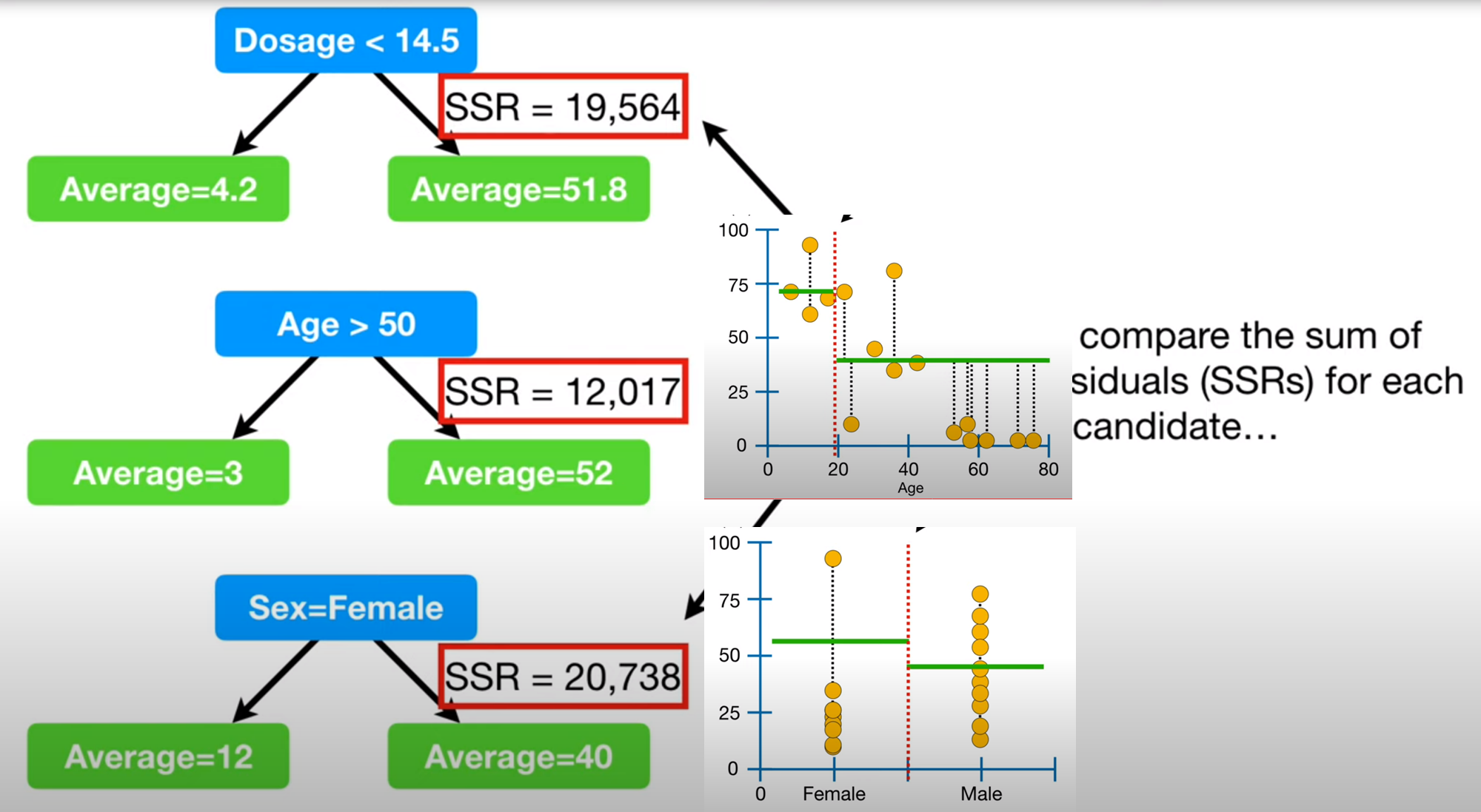
첫 분기점에서 두가지의 컬럼을 랜덤하게 선택하고 두 지니계수를 비교해 첫 분기점으로 삼는다.
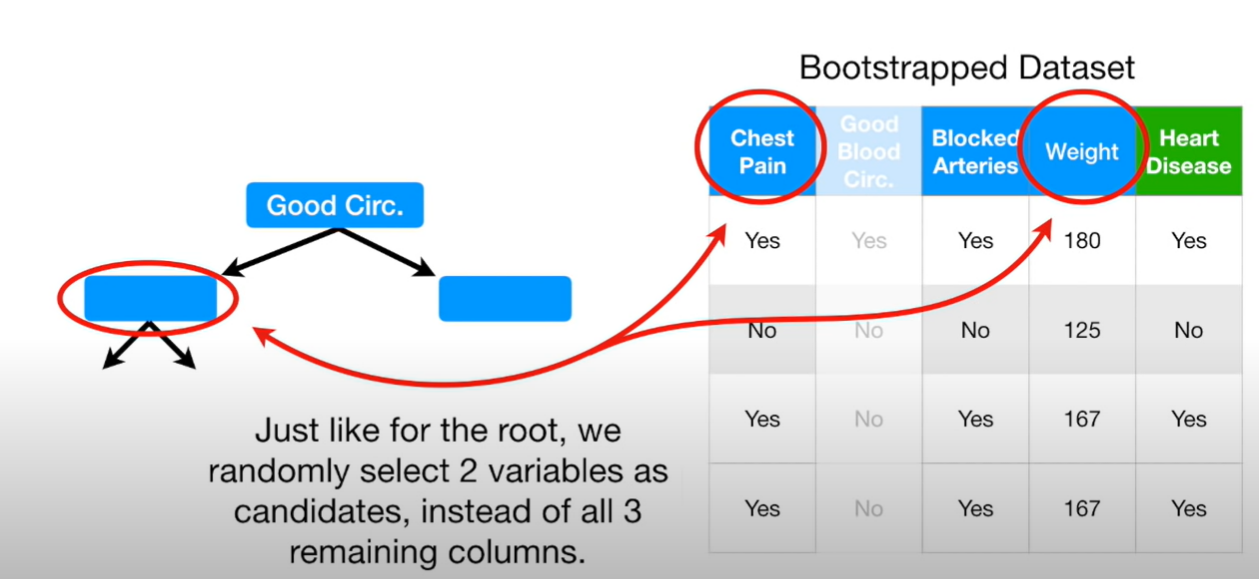
다음 노드들에서도 랜덤하게 두개의 컬럼을 뽑고 그 안에서 질문을 선택한다.
이렇게 트리하나가 완성이 되는 것이다..
이런 2-1~2-2의 과정을 반복하여 여러가지의 트리를 만들게된다
2-3. voting

최종적으로 만들어지 여러트리에 같은 데이터를 통과시켜 결과를 투표를 한 후 높은 표를 받은 결과를 랜덤포레스트의 최종 결과로 반환한다.
이런 총 과정을 익히들었을

배깅이라고한다.
3. 정리
디시전트리를 랜덤으로 뽑은 row와 column을 통해 만든다 x n개
n개의 트리의 결과를 투표하려 최종 리턴
몇개의 row와 몇개의 column을 뽑을지는 여러번 반복시행후 성능을보고 결정(하이퍼파라미터튜닝)
'ML' 카테고리의 다른 글
| [ML] Gradient Boost - Classification (0) | 2022.01.03 |
|---|---|
| [ML] Gradient Boost - regression (0) | 2021.12.30 |
| [ML] Adaboost (0) | 2021.12.29 |
| [ML] Regression Tree (0) | 2021.12.28 |
| [ML] Decision tree (0) | 2021.12.28 |