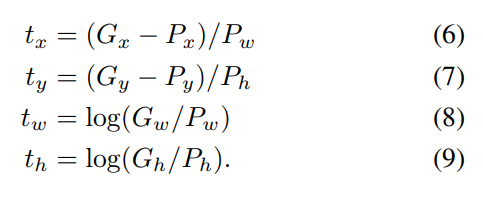1. backtracking 이란
dfs의 개념과 거의 같다고 할 수 있다. 선택을 하며 뒤로 돌아가서 선택을 다시 한다는 개념으로 이해해도 문제가 없을 것 같다. 모든 조합을 탐방하는 경우라고도 할 수 있다. 코테를 공부하며 첫번째로 맞는 벽이라고도 한다
2. 조합

만약 123중에서 숫자를 선택하여 모든 조합을 확인한다고 할 때 위의 이미지의 경우들이 발생할 것이다.
이때 111과 112를 처음부터 끝까지 선택하는 것이아닌 111을 선택하고 마지막 선택을 복원한뒤 즉 110(여기서 0는 선택을 하지 않음을 의미) 으로 돌아간 뒤 112를 선택하는것이 백트래킹의 기본 개요라고 할 수 있다.
(앞으로 이런 순서를 레벨이라고 말할 것이다. dfs에서의 depth와 같다)
이러한 백트래킹에서는 재귀함수를 적즉적으로 활용한다.
이렇게 모든 조합을 살펴본다면 컴퓨터에 부하가 생길 수 밖에 없을 것이다. 이에 보통은 가지치기 조건을 달아 가능성이 없는 조합은 더 이상 가지 않는다.
만약 위의 예시에서 중복을 허용하지 않는다면 100 에서 레벨1의 선택의 옵션에서 1은 제외한 23만이 남을 것이다.
3. 기본코드
#include<iostream>
using namespace std;
int N;
int path[10]; // index : 선택번쨰, value : 해당 선택에서 어떤 숫자를 뽑았는가
int vst[7]; // index : 숫자, value : 해당 숫자를 뽑았었는가?(0 : 안뽑음, 1 : 뽑음)
int sum; // 뽑은 숫자들의 합
void backtracking(int level) {
// 2. 종료조건
if (level == N) { // N개의 주사위를 뽑았다. (idx 0부터 했으니깐)
for (int i = 0; i < N; i++)
cout << path[i] << " ";
cout << "sum : " << sum;
cout << "\n";
return;
}
// i : 1~6이라는 눈
for (int i = 1; i <= 3; i++)
{
// 4. 가지치기(내가 지금 하려는 선택이 괜찮은가?를 판단) <- backtracking
if (vst[i] == 1) continue;
// 3. 기록
path[level] = i; // a번째 주사위에서 i라는 눈을 뽑았다.
vst[i] = 1; // i라는 눈은 뽑혔다.
sum += i;
// 1. 재귀
backtracking(level + 1);
// 3. 기록의 복구
vst[i] = 0;
path[level] = 0;
sum -= i;
}
}
int main() {
cin >> N;
backtracking(0);
return 0;
}