ResNet은 처음으로 인간이 분류할떄의 5%라는 벽을 넘은 최초의 분류모델이자
후속연구에 큰 기여를 한 모델이다. 분류모델뿐만아니라 detection 과 segmentation 부분에서도 좋은 성능을 보였다고 한다.
resnet은 15년에 14년의 googlenet보다 9배깊은 레이어를 활용하여 두배에 가까운 성능을 냈다.
1. Residual learning

resnet 이전에 일반적인 cnn의 구조를 이용의 학습하면 어느정도 이상 깊어진 구조는 training error가 잘 줄지 않는 학습이 잘 되지않는 문제를 가지고 있었다 이에 논문의 저자들이 제안한 방법이
short cup, skip connection, identity mapping 등으로 불리는 Residual learning 이다

이전의 학습된 정보를 conv이후의 결과와 더하는 방법이다
바로 H(x)를 학습하는 것은 어려우므로 대신 F(x) = H(x)-x 를 학습한다. H(x)는 현재 block을 거친 값이고 x는 그 전 까지의 값이니 결국 잔차(Residiual)를 가지고 학습을 했다는 것이다.
concat이 아님에 주의
Residual Mapping은 간단하지만, Overfitting, Vanishing Gradient 문제가 해결되어 레이어를 깊게 쌓을 수 있었고 자연스럽게 성능상승으로 이어졌다.
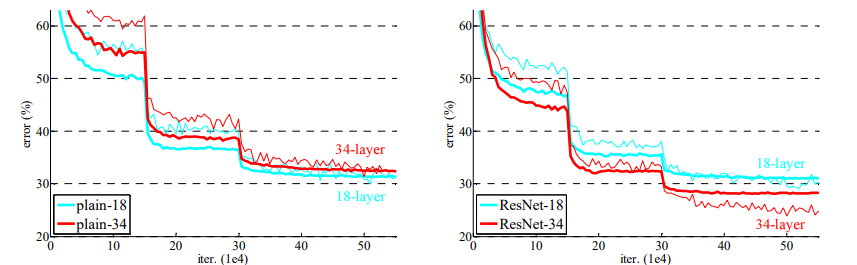
우측 resnet의 경우는 레이어가 깊어짐에도 loss가 더 낮은것을 확인 가능하다
2. archi

주목할만한 점
1) 풀링이 처음에만 사용되고 스트라이드를 이용하여 Feature map의 size를 줄이고 있고 (학습을 통해서 줄인다.)
점선의 short cup에서는 차원을 맞춰주기위해
zero padding
1x1 Filter (Stride = 2)
두 옵션을 사용한다.
2) vgg넷의 영향을 받아 3x3conv를 사용한다
3) bn도 같이 사용한다.
4) GAP를 사용한다.
- 레이어가 깊어지면 앞선에서 특징을 잘 추출했다고 가정하여 연산량을 감소시킬수 있기에~
5) agumentation 사용
3. bottle neck

resnet 50 101 152 에서는 연산량을 줄이기 위해 보틀넥구조를 사용한다.

4. 후속논문
1) 여러 숏컷구조
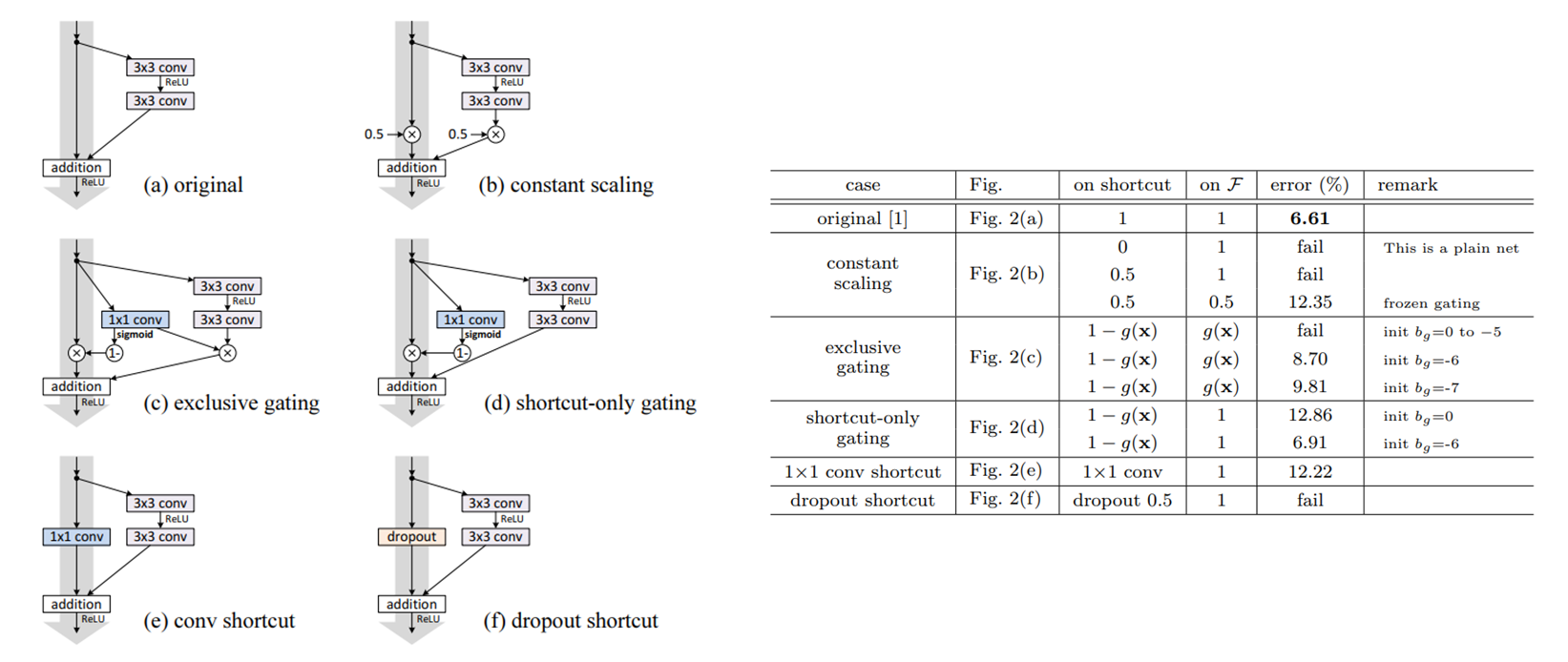
여러가지 숏컷기법을 사용해봣지만 오리지날이 제일 좋은 성능을 보였다.
2) pre-activation

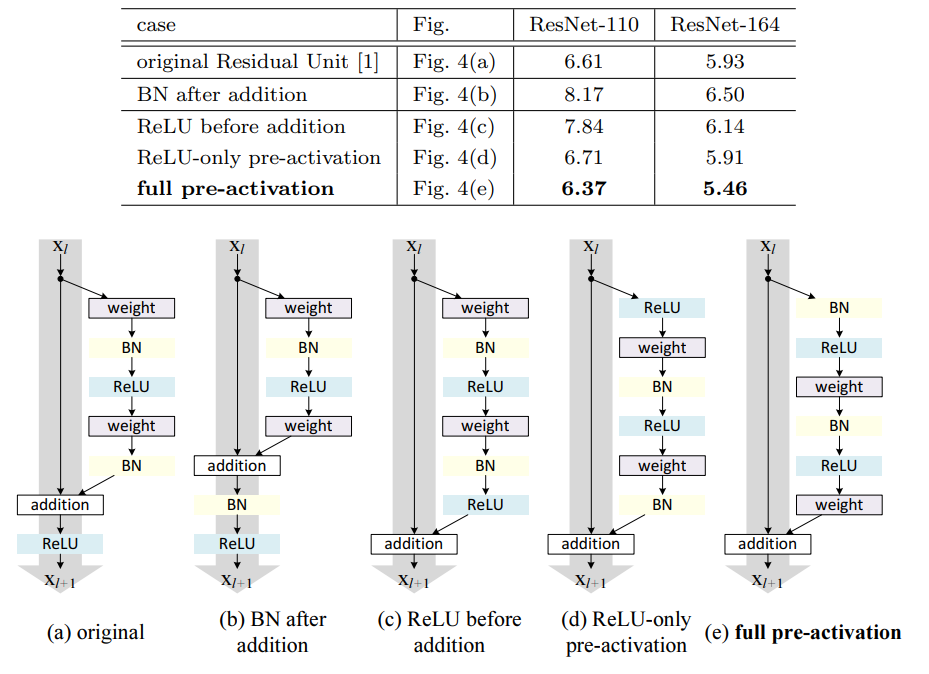
conv 연산 이전에 activation을 거치게하는 preactivation 구조를 제안했다
- 최적화를 쉽게 한다.
기존 ResNet은 short cut 을 거쳐서 입력값과 출력값이 더해지고, ReLU 함수를 거친다. 더해진 값이 음수이면 ReLU 함수를 거쳐서 0이 된다. 층이 깊다면 이 증상의 영향이 더 커지게 되어 더 많은 값이 0이 되어 수렴이 어려워질 것이다.
pre-activation 구조는 더해진 값이 ReLU 함수를 거치지 않아, 음수 값도 그대로 이용하게 된다. 실제로 학습 곡선을 살펴보면 제안된 구조가 초기 학습시에 loss를 더 빠르게 감소시킵니다.
- 과적합방지
pre-activation은 더해진 값이 BN을 거쳐서 정규화 된 뒤에 conv에 입력된다. 따라서 overfitting을 방지한다고 저자는 추측한다.
'CV > classification' 카테고리의 다른 글
| [CV] Xception (0) | 2022.05.03 |
|---|---|
| [CV] Inception V2, V3 (0) | 2022.05.03 |
| [CV] GoogLeNet (0) | 2022.05.02 |
| [CV] VGG Net 리뷰 (0) | 2022.05.02 |
| [CV] Network in Network 리뷰 (0) | 2022.05.02 |