GoogLeNet이후 구글의 연구로 나온 모델이며 영화 인셉션의 이름을 따서 만든 모델이다.
vgg net의 영향을 받아 3x3conv 더 나아가 nx1conv 1xnconv 를 이용하여 구조는 복잡하지만 성능과 연산량을 잡은 효율적인 모델이다.
V2와 V3는 같은 구조를 가지고 최적화 방법만 다르기떄문에 v2를 기준으로 구조를 설명하겠다.
** General Design Principles
논문에 일반적인 cnn구조의 법칙을 설명하는 부분이 있어 간단히 정리해보고자한다
1) representational bottleneck을 피하기 위해서는 극단적으로 feature맵을 줄여서는 안된다
2) 고차원의 것은 분할하여 계산하면 쉽다.
3)
1. Factorizing Convolutions
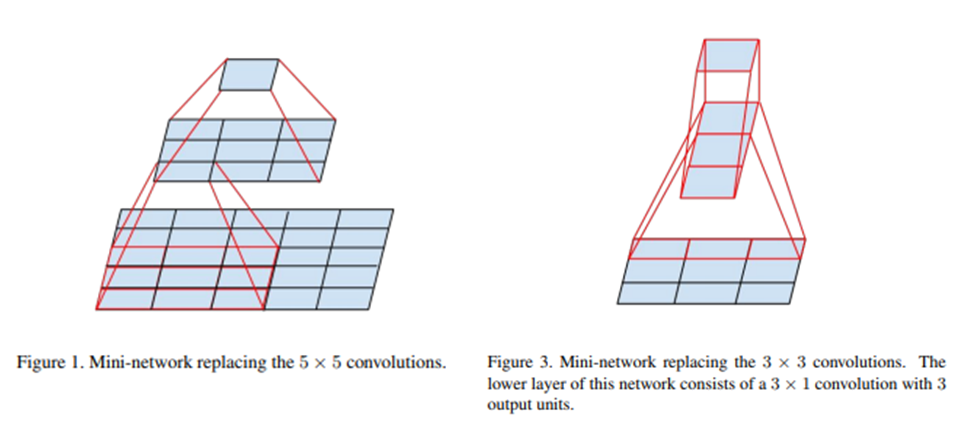
vgg의 영향을 받아 5x5를 3x3 두개의 연속으로 대체하는 방법을 선택했다. 이방법은 파라미터의 갯수면에서 유리한 방법이다.
그리고 3x3을 3x1 1x3 으로 쪼개는 방법을 통해 파라미터수(9 -> 6)를 줄였다.
좀 더 일반화하면 nxn은 1xn과 nx1로 분해 할 수 있고, n이 커질수록 파라미터를 더 많이 줄일 수 있다.

위의 개념으로 일반 인셉션모델 (좌측)을 더욱 발전시켰다
2. auxiliary classifier
googlenet 에있던 auxiliary classifier가 큰도움이 되지않는다는 것을 알고 제외
3. Efficient Grid Size Reduction

representational bottleneck이란 cnn에서 주로 사용되는 pooling으로 인해 feature map의 size가 줄어들면서 정보량이 줄어드는 것을 의미한다.
Figure9를 보면 사이즈를 줄이다 representational bottleneck이 발생하고 풀링을 이후에하면 연산량이 너무 많은 문제점이 있다.
inception V2에서는 representational bottleneck를 막기위해 Figure10 처럼 반은 풀링 반은 stride = 2 conv representational bottleneck을 해소한다고한ㄷ.
4. archi

'CV > classification' 카테고리의 다른 글
| [CV] MobileNet (0) | 2022.05.03 |
|---|---|
| [CV] Xception (0) | 2022.05.03 |
| [CV] ResNet (0) | 2022.05.03 |
| [CV] GoogLeNet (0) | 2022.05.02 |
| [CV] VGG Net 리뷰 (0) | 2022.05.02 |