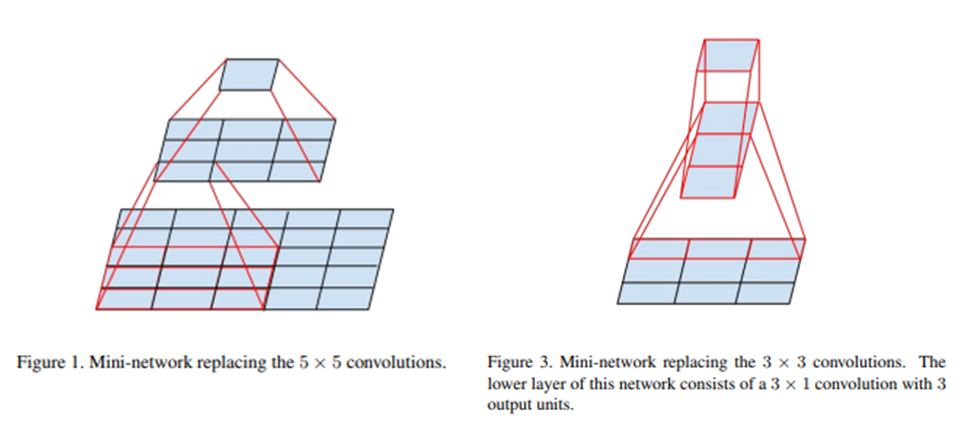
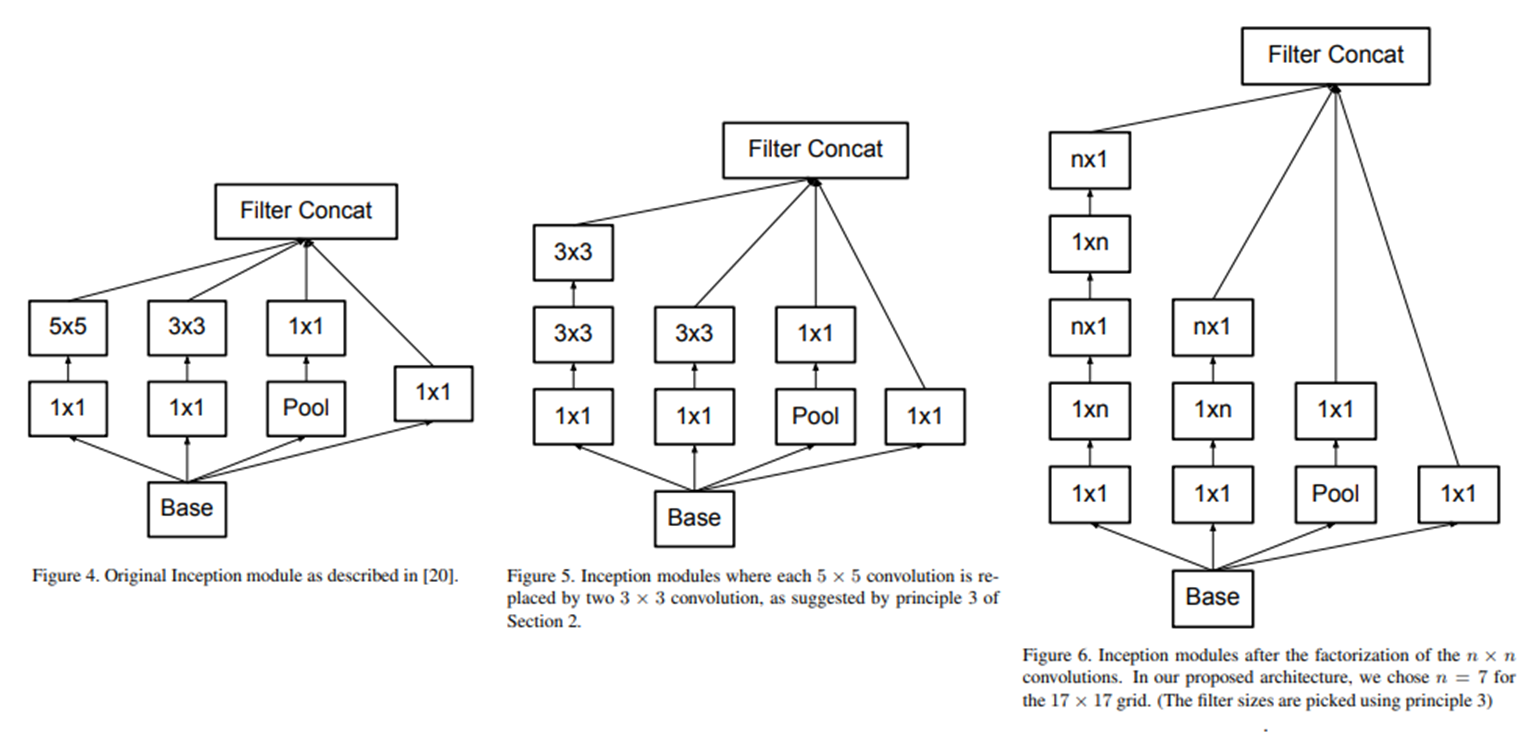
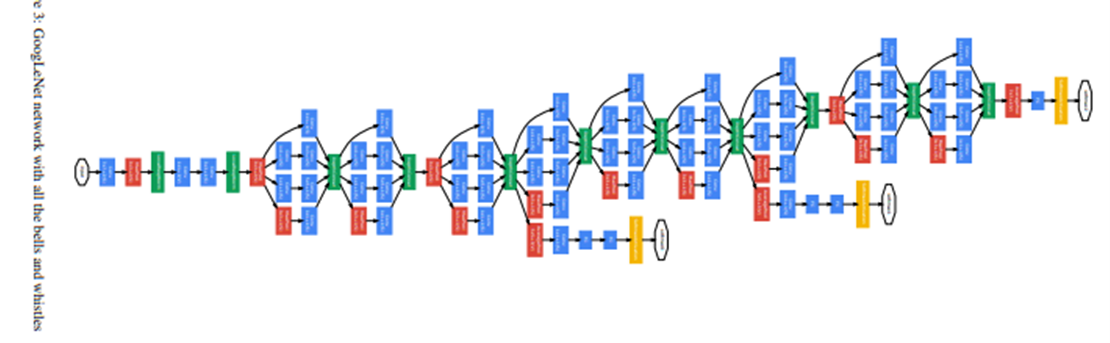
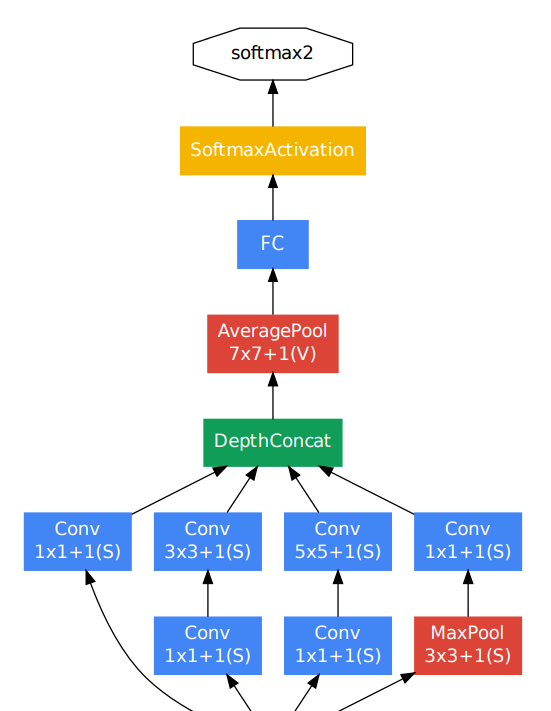
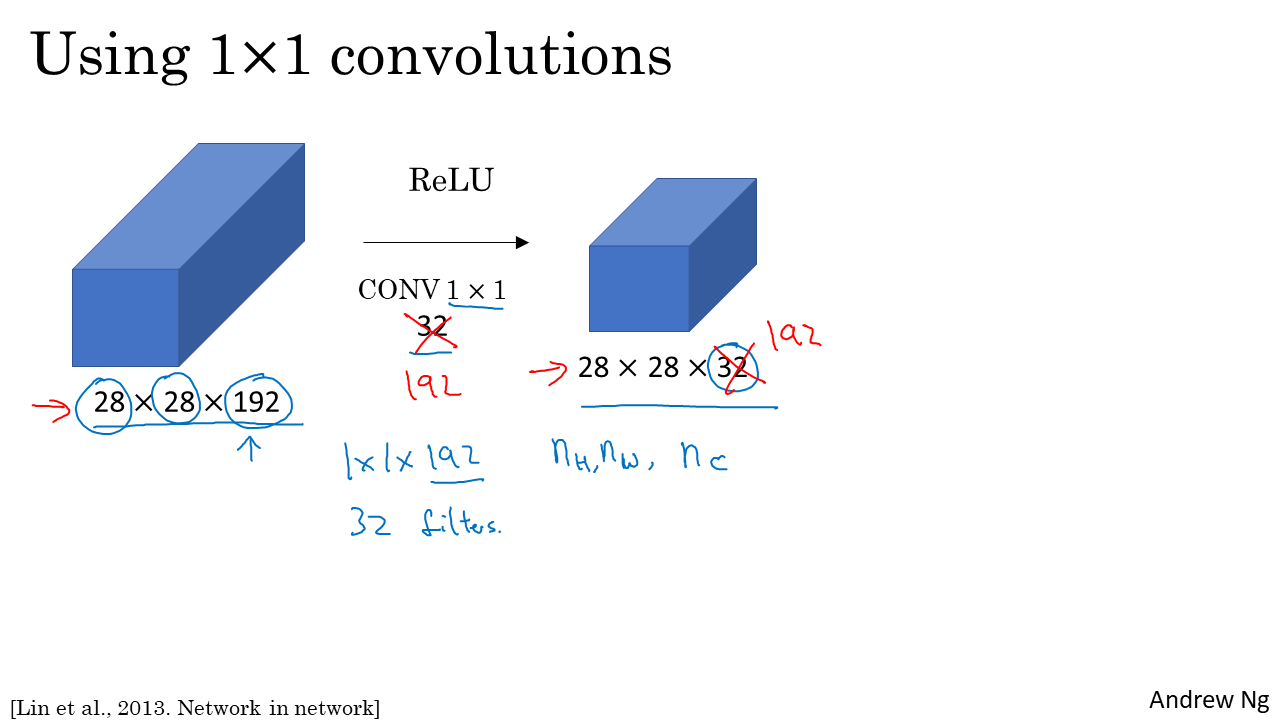
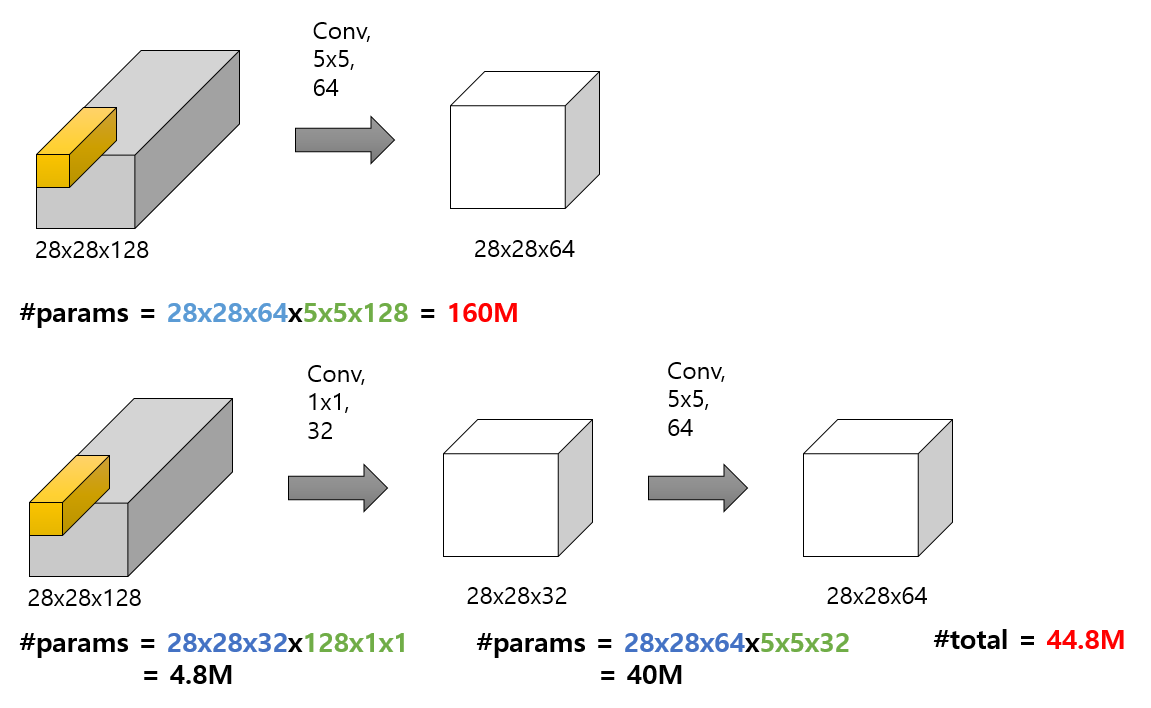
1. Inception 에 대한 해석

일반적으로 사용한는 inception은 좌측 이고 이를 일반화하면 우측 이다. (여러가지의 feature를 학습가능하다는 점이 이어진다 + 채널을 나누어 계산이 쉽다)
저자가 해석하는 inception 이 좋은 성능을 나타내는 이유는
1x1 conv는 채널간 계산(cross-channel correlation)을 실시하고 , 3x3 conv는 각 feature맵 안에서 연산(spatial correlations)을 수행하여 잘 분해해 계산했기 때문이라고 한다.
2. xception
위에서 언급한 일반적인 버전의 inception 모듈의 1x1conv 를 하나로 합치고 3x3conv를 확장한 xception을 제안했다.
채널 방향의 연산은 진행하지 않고, 공간 방향의 3x3 conv을 진행후에 1x1 conv를 진행하는 Depthwise Separable Convoltuion의 순서를 반대로 적용하여
연산량을 줄이고 파라미터의 갯수도 크게 줄일 수 있었다.
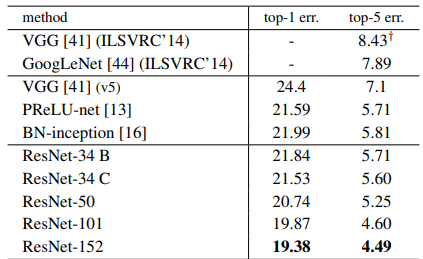
또한 inception v3 보다 나은 성능을 보였다.
3. activation 의 위치
Inception 모듈은 1x1 conv 이후에 ReLU activation을 거친다
xception에서도 pointwise와 depthwise 사이에 activation을 추가할 수 있다. 하지만 xception 에서는 activation을 넣지않는 것이 성능이 더 높게 나왔다고 한다.
저자의 의견으로는 activation이 정보를 바꾸어 놓고 이후의 depthwise는 depth가 없이 연산하기 때문에 오히려 정보손실을 야기할 수 있다는 것이다.
실제로 저자의 의견이 맞는지 왜 inception은 되고 xception은 안되는지에 대해 관해서는 밝혀진게없다
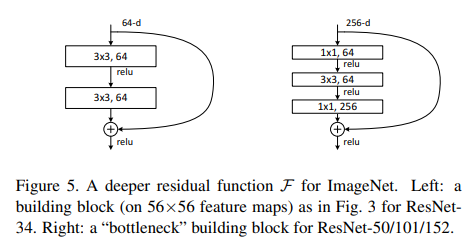
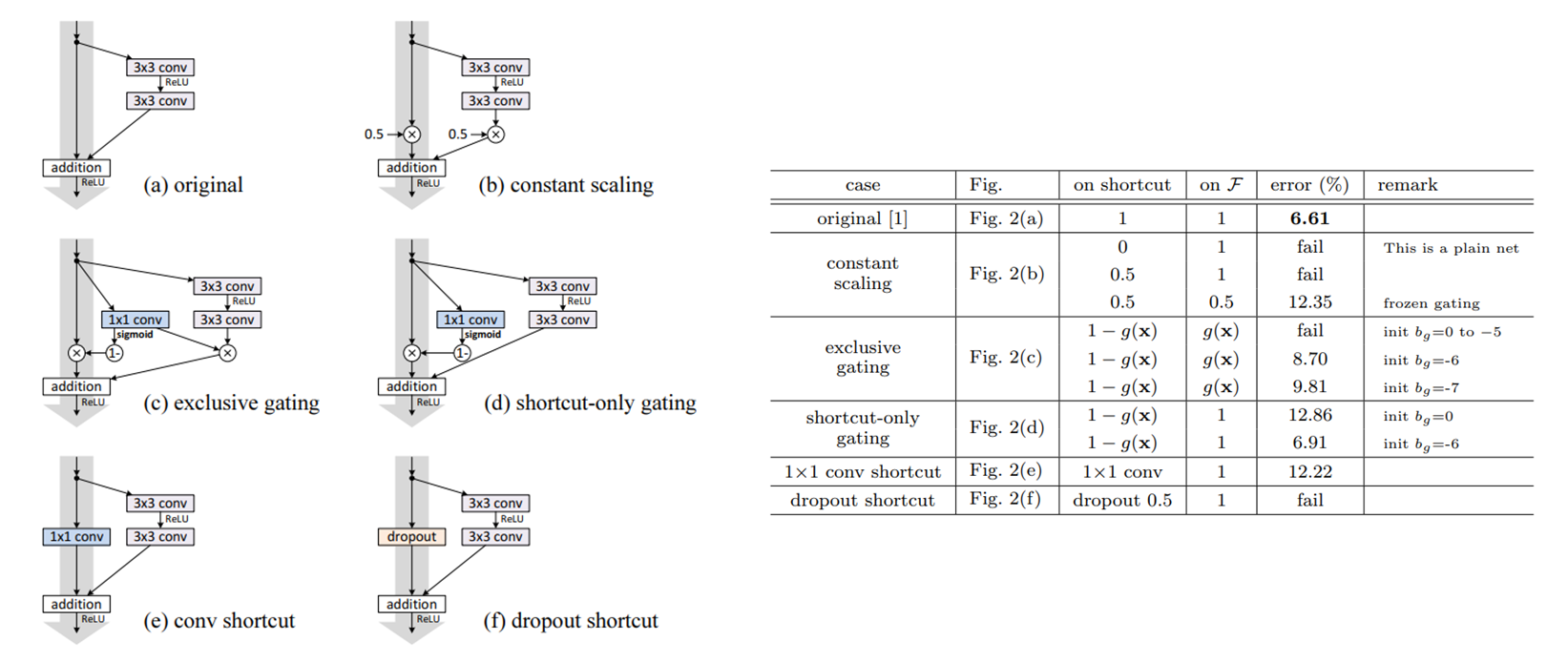
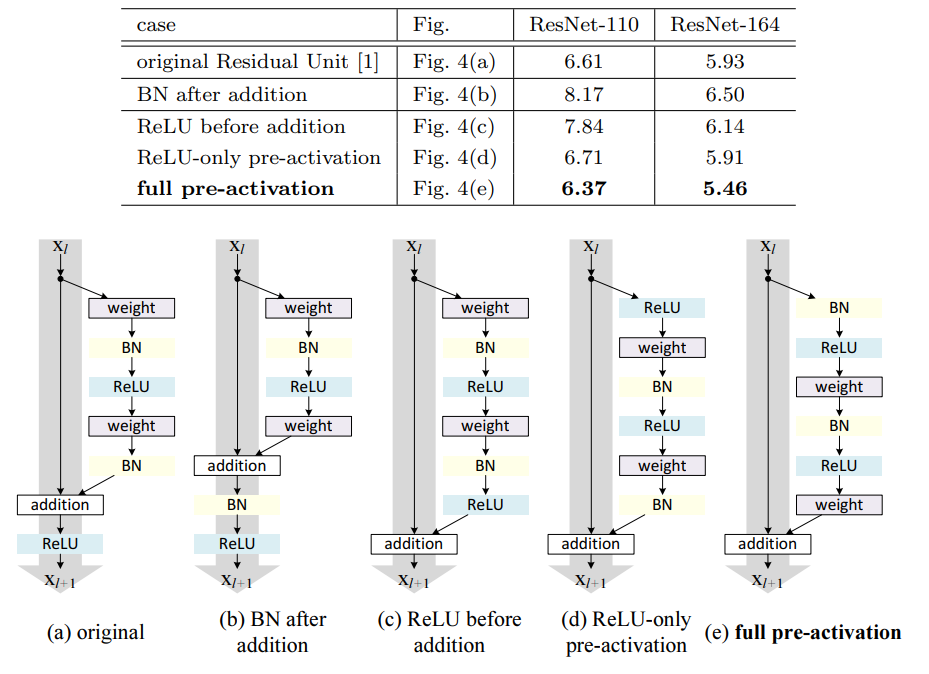
pre-activation resnet에서 언급된 actvation의 위치에 따라서 성능이 바뀐다는 점만 기억하면 될 것같다
4. archi
pre-activation이 보이기도하고
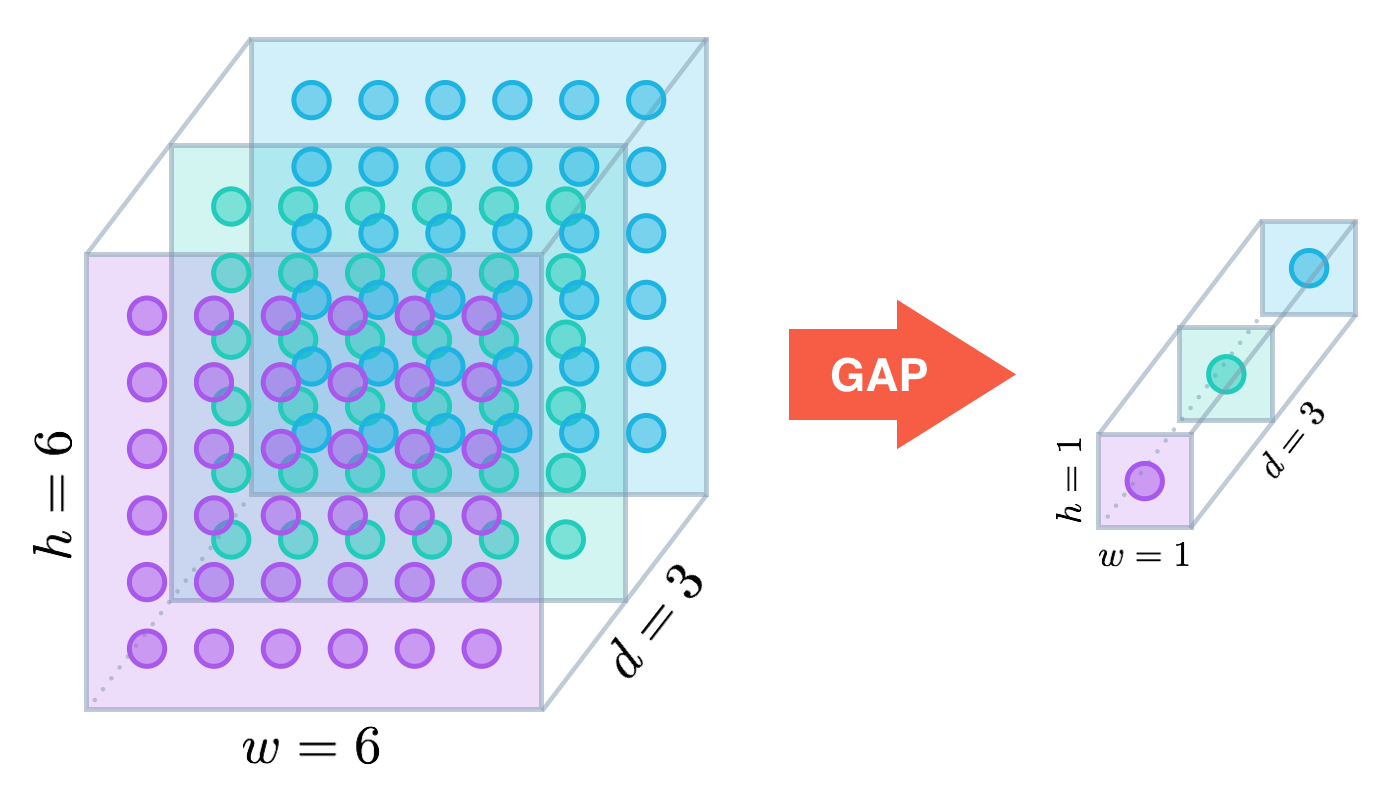
역시나 GAP가 사용되었다
'CV > classification' 카테고리의 다른 글
| [CV] Squeeze Net (0) | 2022.05.04 |
|---|---|
| [CV] MobileNet (0) | 2022.05.03 |
| [CV] Inception V2, V3 (0) | 2022.05.03 |
| [CV] ResNet (0) | 2022.05.03 |
| [CV] GoogLeNet (0) | 2022.05.02 |