웹에 있는 정보를 가져오는 것
!pip install requests, BeautifulSoup
from bs4 import BeautifulSoup
import requestsrequests, BeautifulSoup 모듈을 이용
1. html
- 웹사이트에 요청, html이라는 형식으로 유저에게 정보를 보내줌 파싱(해석),랜더링(가공)을 거처 우리 눈으로 보게됨 이것을 http프로토콜이라고함.
- html
<학교 이름 = 'xx대학교'>
<학과 value = '통계학과'>
<학번 value = '16학번'>
<학생 value = '201611460'> 이우현 </학생>
<학생 value = '201611461'> 이지은 </학생>
<학생 value = '201611463'> 이예지 </학생>
</반>
<학번 value = '17학번'>
<학생 value = '2010711562'> 황예지 </학생>
</반>
<학번 value = '3반'> ...</반>
</학과>
<학과 value = '경영학과'> ....
이런 형식으로 구성됨 하위로 가지를 뻗는 형태 json형식과도 비슷함
이우현 학생에게 접근하려면 xx대학교의 통계학과 16학번인 201611460의 이우현학생 이렇게 접근할 수 있음
각각 부모 자식의 관계로 구성이 됨
네이버 월요웹툰의 html구조를보면

이런식으로 나옴
크롬브라우저의 경우 f12를 누르면 우측에 저런식으로 창이 뜨는데
그 창이 해당 브라우저의 html문서, 화살표를 누르면 자식태그를 볼 수 있게 확장됨
만약 백수세끼라는 제목에 대한 태그를 확인하고 싶다면

빨간펜으로 표시된 버튼을 누르고 백수세끼라는 제목으로 누르면 우측창에 해당하는 태그 경로를 알 수 있음
이런 경로를 xpath라고도 함

원하는 부분에 마우스 우클릭을하면 copy - > copy xpath를 클릭하면 해당 하는 부분의 xpath를 복사해준다
//*[@id="content"]/div[1]/ul/li[2]/dl/dt/a/strong
이게 백수세끼의 xpath이다.
<strong title="백수세끼">백수세끼</strong>
이 구문을 보면 스트롱이라는 태그는 title이라는 속성을 가진다. title값은 '백수세끼'이다.
그리고 </strong>으로 strong이라는 태그의 정보를 종료하는데 주황값으로 표시한
부분에는 택스트가 들어간다. 보통 우리가 접근하는 값은 이 값이다.
이런 속성정보는 태그이름이 동일한경우 내가 원하는 태그에 접근하고 싶을 때 유용하게 사용된다.
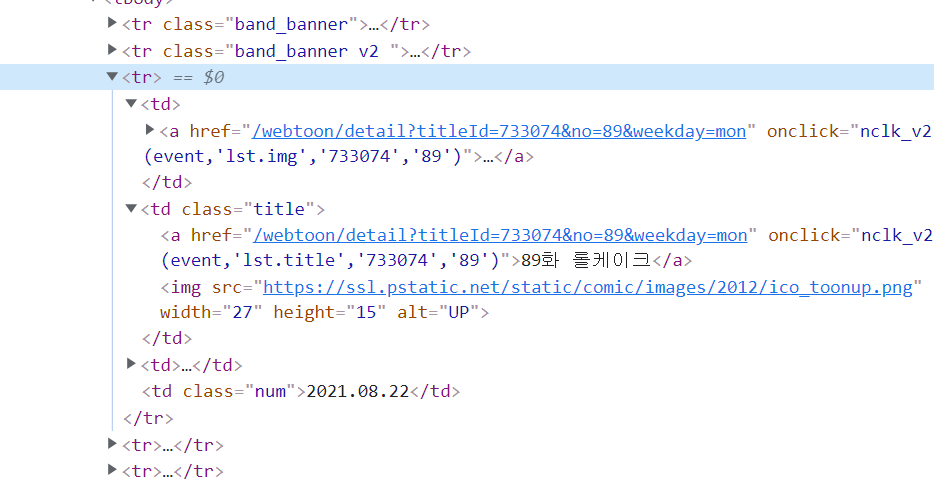
td 태그가 많은데 제목에 접근하고 싶다면 td태그이면서 class가 title인 녀석에 접근하면 될 것이다.
2. requests
import requests
url = 'https://comic.naver.com/webtoon/list?titleId=733074&weekday=mon'
res = requests.get(url)
res.raise_for_status() # 오류가 생기면 셀종료
res.text리퀘스트 패키지를 이용해서 이렇게 네이버 월요웹툰의 html을 가져올 수 있다.
requests의 get명령어를 사용하면 해당 url의 html을 가져올 수 있고
res.raise_for_status() 명령어로 성공적으로 페이지를 가져왔는지 확인할 수 있다.
만약 제대로 가져오지못했다면 에러가 생겼을 것이다
text 명령어를 통해 html을 확인할 수 있다.
3. BeautifulSoup
html에서 검색의 역할을 해준다고 생각하면 편하다,

from bs4 import BeautifulSoup
url = 'https://comic.naver.com/webtoon/list?titleId=733074&weekday=mon'
res = requests.get(url)
res.raise_for_status() # 오류가 생기면 셀종료
soup = BeautifulSoup(res.text, 'lxml')
print(soup.find('td', attrs = {'class':'title'}))
print('-'*50)
print(soup.find_all('td', attrs = {'class':'title'}))<td class="title">
<a href="/webtoon/detail?titleId=733074&no=89&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','89')">89화 롤케이크</a>
<img alt="UP" height="15" src="https://ssl.pstatic.net/static/comic/images/2012/ico_toonup.png" width="27"/>
</td>
--------------------------------------------------
[<td class="title">
<a href="/webtoon/detail?titleId=733074&no=89&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','89')">89화 롤케이크</a>
<img alt="UP" height="15" src="https://ssl.pstatic.net/static/comic/images/2012/ico_toonup.png" width="27"/>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=88&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','88')">88화 컵과일</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=87&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','87')">87화 짜장라면</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=86&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','86')">86화 찐만두</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=85&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','85')">85화 어묵</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=84&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','84')">84화 로제 떡볶이</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=83&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','83')">83화 하ㅇ정식</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=82&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','82')">82화 김치부침개</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=81&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','81')">81화 크로플</a>
</td>, <td class="title">
<a href="/webtoon/detail?titleId=733074&no=80&weekday=mon" onclick="nclk_v2(event,'lst.title','733074','80')">80화 주꾸미 볶음</a>
</td>]requests 모듈로 가져온 html정보로부터 soup객체를 생성하고
find를 사용하면 td태그 중에서class가 title인 첫번째 태그를 가져온다
find_all을 사용하면 td태그 중에서class가 title인 태그들을 리스트형태로 가져온다.
만약 우리가 제목을 알고 싶다면.
titles = soup.find_all('td', attrs = {'class':'title'})
for title in titles:
print(title.a.get_text())89화 롤케이크
88화 컵과일
87화 짜장라면
86화 찐만두
85화 어묵
84화 로제 떡볶이
83화 하ㅇ정식
82화 김치부침개
81화 크로플
80화 주꾸미 볶음titles에 td태그 중에서class가 title인 태그들을 저장하고 포문으로 각각 타이틀들의 a태그의 텍스트에 접근한다.

각각 회차의 링크를 가져오고 싶다면
for title in titles:
print('https://comic.naver.com' + title.a['href'])https://comic.naver.com/webtoon/detail?titleId=733074&no=89&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=88&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=87&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=86&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=85&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=84&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=83&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=82&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=81&weekday=mon
https://comic.naver.com/webtoon/detail?titleId=733074&no=80&weekday=mon이렇게 된다.
하위 태그로 들어가고 싶다면 td.a 이렇게 .으로 이어서 접근하면되고 해당태그안의 속성에 관심이 있다면;
a['href']이렇게 접근하면 된다.
4. 최종실습
from bs4 import BeautifulSoup
import pandas as pd
df= pd.DataFrame()
url = 'https://comic.naver.com/webtoon/list?titleId=733074&weekday=mon'
res = requests.get(url)
res.raise_for_status() # 오류가 생기면 셀종료
soup = BeautifulSoup(res.text, 'lxml')
titles = soup.find_all('td', attrs = {'class':'title'})
for title in titles:
name = title.a.get_text()
link = 'https://comic.naver.com' + title.a['href']
data = {'title':name, 'link':link}
df = df.append(data, ignore_index=True)
display(df)판다스에서 나타내는 과정에서짤려서 실제로 접근은안되지만 풀데이터프레임으로 접근시 가능
'웹크롤링' 카테고리의 다른 글
| [ 웹크롤링 ] 셀레니움 스크롤하기, 유튜브 댓글크롤링 (0) | 2021.08.26 |
|---|---|
| [ 웹크롤링 ] 셀레니움 설치, 동적 크롤링 - bs4, requests로 안되는 페이지 크롤링하기 (0) | 2021.08.25 |
| [ 웹크롤링 ] 카카오api를 사용하여 지오코딩하기 위경도가져오기 (0) | 2021.08.24 |
| [ 웹크롤링 ] header 크롤링 서버거부 user-agent (0) | 2021.08.23 |
| [ 웹크롤링 ] 공공 API이용하기 공휴일 정보 가져오기 (3) | 2021.08.23 |